
Is it me, or do we really see way more imaging visual tech announcements popping up each week that have game-changing potential? In any case, here are 6 visual tech announcements from just the last couple of weeks that each could completely change how we view, capture, or edit visuals.
And yes, these technology announcements are “way out there” – some more than others. So don’t throw away yet your 2D camera, your 360 camera, your 3D modeling software, your light source, your AR glasses, or your expensive lidar sensor.
DALL-E 2. Creating better images through textual prompts. Who needs a camera anyway?
OpenAI released a new version of DALL-E, its text-to-image generation program. Compared to version 1.0, DALL-E 2 generates more realistic and accurate images with 4x greater resolution.
Created when saying, “A painting of a fox sitting in a field at sunrise in the style of Claude Monet.”

DALL-E 2 also includes new capabilities, such as editing an existing image from a natural language caption:

Researchers can sign up online to preview the system, and OpenAI hopes to make DALL-E 2 available for use in third-party apps at a later stage.
Max Planck Institute for Informatics & the University of Hong Kong. High-resolution 3D-capable image synthesis. Who needs a 3D camera anyway?
Creating 2D synthetic images through GAN (Generative Adversarial Networks) from scratch, text (see the DALL-E 2 above) or a combination of images is one, but doing that to generate rotatable high-resolution images is quite another.
Researchers from the Max Planck Institute for Informatics and the University of Hong Kong have introduced StyleNeRF, a 3D-aware generative model trained on unstructured 2D images that is capable of synthesizing photorealistic images with a high level of multi-view consistency. Their 3D-aware GAN model also allows for control of the 3D camera pose, as well as specific style attributes.



NVIDIA AI Research Lab. AI to create 3D objects. Who needs 3D modeling anyway?
NVIDIA researchers have developed a GANverse3D application that converts flat images into realistic 3D models that can be visualized and controlled in virtual environments – eliminating the need for 3D modeling.
A single photo of a car, for example, could be turned into a 3D model that can drive around a virtual scene, complete with realistic headlights, taillights, and blinkers.
First, to generate a dataset for training, the researchers harnessed a generative adversarial network, or GAN, to synthetically create variations of a photo depicting the object from multiple viewpoints — like when a photographer walks around a parked vehicle, taking shots from different angles.
These multi-view images were then plugged into a rendering framework for inverse graphics, the process of inferring 3D mesh models from 2D images.
Once trained on multi-view images, GANverse3D needs only a single 2D image to predict a 3D mesh model. This model can then be used with a 3D neural renderer that gives developers control to customize objects and swap out backgrounds.



UC Irvine. AI to shoot full-color images in total darkness. Who needs light anyway?
Scientists from UC Irvine have developed an AI-based imaging algorithm that enables a monochromatic camera to digitally render a visible spectrum scene to humans when they are otherwise in complete “darkness.”
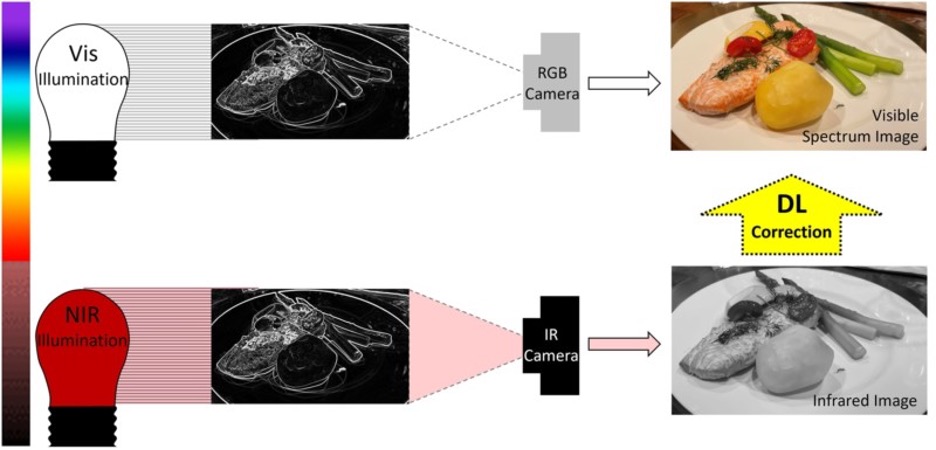
Conventional cameras acquire R, B, and G pixels of data to produce a color image perceptible to the human eye. The researchers investigated if a combination of infrared illuminants in the red and near-infrared (NIR) spectrum could be processed using deep learning to recompose an image with the same appearance as if it were visualized with visible spectrum light.
Yeah, it works – sort of, and limited to human faces so far – with a choice of 3 different deep learning architectures:

Mojo Vision. AR through contact lenses. Controlling a MicroLED display with a flick of your eyes. Who needs AR glasses anyway?

A 1.0 product is still a ways to go, but the investment community is betting on Mojo Vision being able to pull it off, having funded the startup with $205M to date.
Stanford University. Depth-measuring for the rest of us. Who needs expensive bulky lidar anyway?
Researchers at Stanford University have developed a new compact, energy-efficient, and high-resolution way to measure depth while using standard image sensors – they call it “standard CMOS lidar.”
How exactly does their solution work? In essence, it places an acoustic modulator between the lens and the camera. This transparent crystal is made out of lithium niobate and is charged by two transparent electrodes. Working in concert with the image sensor, the system can modulate the light data coming through the lens and determine where an object is. (You can read more here).
The researchers point at two intriguing opportunities:
- First, it could enable megapixel-resolution lidar – a threshold not possible today. Higher resolution would allow lidar to identify targets at a greater range;
- Second, any image sensor available today, including the billions in smartphones and DSLRs, and various other camera systems, could capture rich 3D images with minimal hardware additions.

And a few more things…
EyeEm. Now we know:
$40M. Talenthouse, an aggregator of content creators, whose visual content Talenthouse commissions to brands for their own social media channels, acquired EyeEm in June of last year (EyeEm is a Visual 1st alumnus). As the deal was for mostly stock, how much was it really worth, many wondered? Well, Talenthouse just went public on the SIX Swiss Exchange, making the value of that stock more tangible. The short answer: stock + cash were worth roughly $40M. At the time of the acquisition, EyeEm had raised $24M. Not the kind of stellar returns VCs aim at, but the once high-flying photo startup did yield a positive return.
Apple. iMovie 3.0:
late to the party. It took a while, but iMovie – first released in 1999 on the Mac and in 2010 on iOS – has become mobile- foremost. Version 3.0 is now launched for iPhone and iPad, and no word if or when it will make its way to the Mac. iMovie’s new features, template-based Storyboards, and a Magisto-reminiscent instant video creation feature called Magic Movie, follow industry trends to enable users to create good-looking video clips through just a few steps.
allcop. Acquires omaMa.
German photo print product provider allcop acquires omaMa, a personalized print product provider focused on products for babies and grandchildren. omaMa’s products include personalized clocks, pillows, stuffed animals, and various photo print products.
TikTok. Snap and Meta, here we come.
TikTok launches Effect House, its own AR development platform, aimed at creators to build AR effects for use in TikTok’s video app.
Google. Multi-format search.
Of course, you can enter text to search on Google. And then Google Lens enabled you to search by submitting a photo. Now Lens offers (in beta, in the US) a combination of text and visual search. After submitting your image, e.g. a pair of sneakers, you can click the “+ Add to your search” button to add text, e.g. “trail running,” which should return links to trail running shoes.
Picaboo Yearbooks & Entourage Yearbooks.
Consolidation in yearbook land. Entourage Yearbooks acquires Picaboo Yearbooks. Combined, Entourage and Picaboo Yearbooks will service more than 10,000 schools. Picaboo Yearbooks was an offshoot of photo merchandise company Picaboo.com. Both companies helped to modernize the yearbook industry from standard six-week turnaround times to three weeks; from binding contracts to flexible, non-binding agreements; from long runs to variable quantities for the same price; and from physical books to e-yearbooks.
main image : Photo by Aideal Hwa on Unsplash
Author: Hans Hartman
Hans Hartman is president of Suite 48 Analytics, the leading research and analysis firm for the mobile photography market and organizer of Mobile Visual 1st, a yearly industry conference about mobile photography.