
While big companies like Google, Yahoo, Microsoft, Facebook pour millions into visual content recognition in order to make sense of the billions of images uploaded to their services, smaller companies offer the same solutions to anyone interested in using deep learning to classify images and videos automatically. Straight out of Bulgaria and with years of on the field experience for a variety of companies, Imagga is one that certainly carries its weight in this field. We caught up with founder and CEO Georgi Kadrev to learn more:
A little about you, what is your background?
I’m in computer programming since I was 11, almost for 20 years now, and I’ve been a laureate of many competitions in informatics in my high school and student years.

I fell in love with computer vision and image processing when I was 16, starting a project about image morphing that was later extended to an automated facial morphing based on neural networks. At the age of 22 I was bitten the entrepreneurial bug and decided that there are so many technology opportunities in the field of image recognition that are not applied in practice and are left on the shelf in the research labs of universities and big corporations, rarely seeing any publicity or commercial applications.
Since then my mission, as part of a great team, has uninterruptedly been to democratize image recognition, making it accessible to everybody.I’ve learned some things the hard way so I’m also paying back to the community by sharing startup lessons learned to the students in the M.Sc. classes in Technology Entrepreneurship in Sofia University.
This is also where I’m working (quite sparsely :)) on my Ph.D. thesis, that basically reflects the technological lessons learned in Imagga. I try to workout and meditate a bit every day so I can keep up with the 80-100 hours work weeks 🙂
Explain Imagga. What does it solve and how does it work?
Imagga is an automated image tagging API that empowers business and developers to build apps that understand images.
It’s well known that in the last few years, with all kind of devices, have been taken more photos than in the whole previous history of photography. Also, more than 2 billion images are shared daily just in social networks alone. The problem Imagga addresses is that all this visual content lacks metadata – businesses are practically blind about the actual visual content that their users, employees or partners generate.
Imagga solves that by providing a very easy to use RESTful API (in the cloud or on-premise) that consumes image and video content and returns a set of tags (keywords) or categories that describe what’s on the photo. We recognize classes of objects (‘pen’, ‘computer’, ‘dog’, ‘beer’, ‘man’, etc.), scenes (‘outdoor’, ‘beach, ‘mountain’, etc.) and concepts (‘event’, ‘business’, ‘love’, etc.).
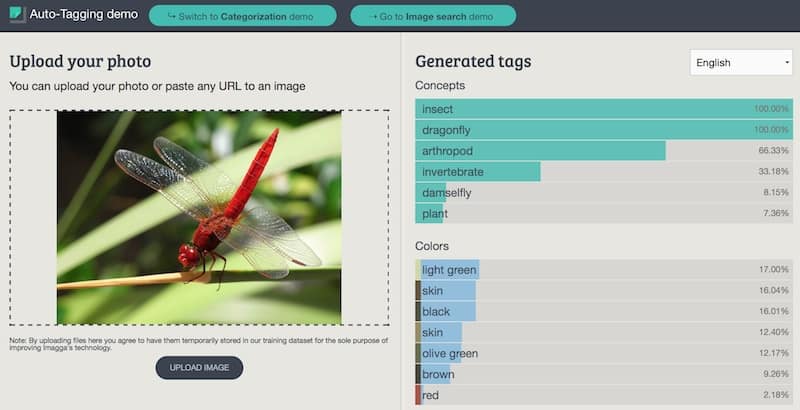
There are a few companies offering services like yours. How is Imagga better?
We were visionary enough to foresee the upcoming boom of visual content more than five years ago when it wasn’t as obvious as it is now. We still hear the words we were saying, back in 2009 from the small country of Bulgaria, echoing in some of the new players trying to enter the market.
We were bold enough to start building a portfolio of image recognition services while we were still in “the winter” of machine learning and build a profitable and organically growing company that is not that dependent on investors’ mood swings.
This early start allowed us to gain a lot of experience managing the right customer expectations when we talk about automated solutions, and to have a pretty good understanding of their actual needs. Based on that experience we build an API that suggests the largest number of tags (very high recall rate), which could be thresholded if needed while still having a very high precision rate in the general case.
Something that has also played quite well for us is our exclusive focus on visual content and the fact that we have a set of complementary image analysis services – such as precise color and compositional analysis and categorization, in addition, to the flagship tagging technology.
We continue to innovate guided by customer demand and a few exciting major features are upcoming early next year.
Last but not least, we are always aiming to make this technology as accessible as possible. That’s why we keep a lot of focus on its simplicity of use and the distribution channels – our API is accessible via multiple cloud platforms like Blitline, Cloudinary, AYLIEN, and S4, which makes it even more convenient for integration in various scenarios.
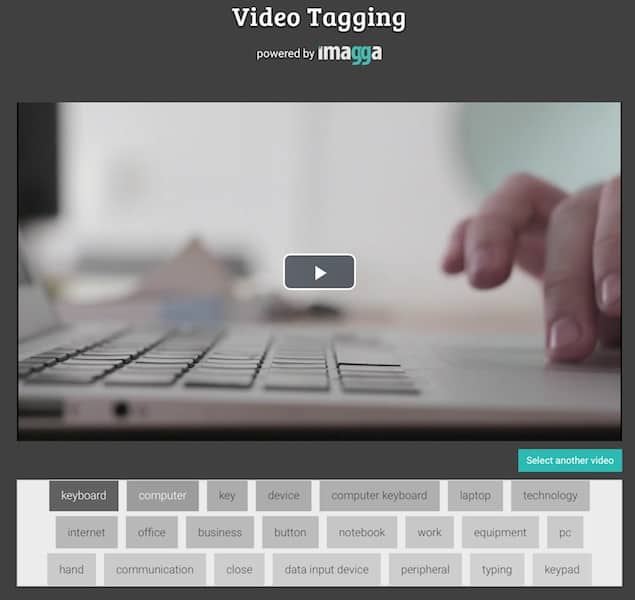
How many categories can you now recognize? How fast is it growing?
Currently, we recognize more than 23 000 terms. Part of them are physical objects, others are scenery, conceptual or semantically expanded keywords (for example ‘car’ -> ‘vehicle’).
We are now experimenting with two paths expanding it further – either adding more and more terms to the general learning sets and/or digging more into the verticals.
Are they categories where you are more advanced (emotions, concepts, relationships for example)?
We haven’t specialized in something particular with our general tagging. The way we select what to learn it to recognize is purely based on statistics what are the most popular types of content available online.
In practice, we are very strong in recognizing classes of physical objects and types of scenes.
We also have a powerful custom categorization framework that can enable numerous deeper specializations for the particular use-case or customer.
Google, Yahoo, Facebook, Microsoft, IBM, Pinterest and other very large companies all have their own very well-funded research on content recognition. How do you compete?
Being a strong believer in the B2D model and the rise of developer-centric services we are focused on building a great service, backed by a heavily practical technology.
This is quite close in terms of dynamics to the consumer models, so we tweak our product and release new features every few weeks, if not days. This is the kind of expectation that a developer has and the big players haven’t proven to be very good at that yet.
We see that even enterprise customers prefer not to (exclusively) depend on huge players. We would gladly give them a good run for their money if they try to step into our market, instead of just using these kinds of technologies for internal purposes 🙂
Who is Imagga typical client?
First of all, we believe that image and video content in the mid-long run would become just the media that almost any business channels somehow – something as inherent as having a website nowadays for example. That’s why we keep building a solid platform instead of а specific vertical solution.
At the same time we know the right way to build a platform is case by case, with real customer needs in mind. Naturally our customer portfolio consists of personal cloud services, photo sharing and selling sites, advertising agencies and any other type of business that has a lot of user-generated images or videos and want to make them searchable and/or extract some other value out of them.
We’ll be sharing more and more case-studies in the upcoming months, to demonstrate how Imagga’s API can be used even beyond the obvious use-cases, by ambitious and visionary early adopters.
Geographically – we are servicing some of the strongest brands in the US, Europe, and Asia – they just love the product and the technology and don’t mind where are we coming from.
Not surprisingly for a nation of early adopters – more than 35% of our customer base is in the US and we are planning for some physical presence soon.
You just launched multi-language auto-tagging. Besides English, what language do you see traction on?
It’s brand-new feature that we were keeping private for a few months before the public launch a week ago. So far German, French and Italian are the most actively used languages, besides English.
In addition to these we see increased interest in Spanish and Portuguese, thanks to the publicity we got recently, after winning the best “Technology for the big players” prize at South Summit – one of the biggest startup events for South European and South American companies.
Some of your clients use your technology for image classification and pattern recognition. Can you explain more?
It’s hard to describe the universe with a general solution though we aim for such goal in the long run with our tagging.
At the same time, it’s very convenient to have specific categorization technology that recognizes the particular type of content that really matters for a customer. We give them the ability to define their own categories and train the system with them.
Instead of offering a self-service solution, we believe it’s important to help them design the lists of categories and advise them how to gather the sample images for each category. As a next step, we do several iterations of learning parameters optimization and finally present them the optimal model learned.
Using the above approach we are very close to 100% acceptance rate of the learned models.
This type of categorization solution is very convenient for businesses that have been doing it manually before – they already have high-quality training data and not just understand the problem but have already tried to solve it somehow.
The use-cases are really more than we can typically imagine. Some of the funny ones that I can recall right now are sorting out trash in an experimental project by top Asian university, or recognizing if the person is a hipster at the bar entrance with an interactive installation 🙂
Imagga is based in Bulgaria. Is that an advantage or a challenge?
Thanks for that question! I can speak about that for hours but will try to keep it concise 🙂
I must admit that some people may still perceive Bulgaria as a small post-socialistic country that they can hardly locate on the map. But a lot of things has changed, especially after we joined the European Union in 2007. Currently, it’s a quite nice place to do business, with a stable economy and just 10% corporate tax.
Even more importantly, Bulgaria has a very strong tradition in computer science – the first International Olympiad in Informatics was organized and hosted by Bulgaria in 1989 and since then Bulgaria has been among the top performers there, along with the US, Russia, China, and Korea.
More recently, in an overview of the tech talent scene worldwide Venture Beat stated that Bulgaria has the highest average reputation among top users in the world.
We also have success stories like Chaos Group which is the global leader in ray-tracing with their V-ray and Telerik which was acquired by Progress Software for $262M end of last year. We are happy to have two of the Telerik’s founders as business angels and advisers in Imagga.
At the end of the day, we see that what matters most for the customers are how good the product and the technology are, and we are happy to deliver on and beyond their expectations!
What would you like to see Imagga offer that technology cannot yet deliver?
Machine learning has really progressed in the last three years thanks to the advancements in hardware and some publicly accessible datasets. While the first aspect – the hardware – still continues to advance rapidly we see that the quality and the quantity of the data sets is what can make the difference between a good and a mediocre product. We are working on innovative ways to gather and learn from data and believe this will show very soon.
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”
On Imagga carrying weight in the image recognition and tagging Platform-as-a-Service space – https://t.co/pnlQCws9GG