
As generative AI continues to infiltrate everything from smartphone cameras to image editors, one deceptively simple question remains unresolved and increasingly urgent: How much AI involvement is enough to call something AI-generated?
It is not just a technical question or a legal one. It is a question about truth, trust, and the very language we need to navigate a future in which “real” becomes negotiable.
The Blurred Line Between Tool and Author
What once began as deterministic image processing, simple sharpening filters, exposure correction, or skin smoothing , has evolved into something fundamentally different. Today, AI not only enhances creative work. It generates, reshapes, and even originates it. And we no longer know, with any certainty, when the hand of the human ends and the eye of the machine begins.
A designer who asks Firefly to remove a background has technically generated content with AI. Similarly, the photographer who edits in Photoshop can now utilize machine learning to perform even basic corrections. So has the smartphone user whose device silently reconstructs a sky, boosts contrast, or replaces facial features with what the algorithm thinks they should be.
If AI quietly shapes the final image, is it still trustworthy? And does it even still belong to the human who initiated it?
And provenance, while valuable, does not always resolve the issue. In many cases, it is unknown. And even when it is, we lack historical references or norms to guide whether to trust it. Which means, all too often, the burden of credibility falls back on the image itself.

Labels Without a Line
Much of the current effort to promote transparency, whether through visible watermarks, metadata, or platform labels, assumes we know what deserves a label in the first place. We don’t.
Meta’s Watermarking and Metadata for GenAI Transparency at Scale – Lessons Learned and Challenges Ahead illustrates this confusion with unusual honesty. When the company began labeling third-party content as “Made with AI” based on C2PA and IPTC metadata, users pushed back, not because the label was inaccurate, but because it felt disproportionate. Many had used nothing more than automated retouching or color correction, unaware that these tools now flag as AI-enhanced. To them, the label was misleading, even stigmatizing.
In response, Meta quietly shifted. It changed its labeling to “AI Info,” moved labels for lightly edited images into contextual menus, and kept surface labels for wholly synthetic media. This evolution reflects a deeper truth: people care less about whether AI was used, and more about whether what they’re seeing is believable.
As the study itself concludes:
“Our research findings suggest that concerns about GenAI transparency are less about whether a piece of content has been GenAI-created or altered… and more about whether such content, particularly visual content, is ‘real.’”
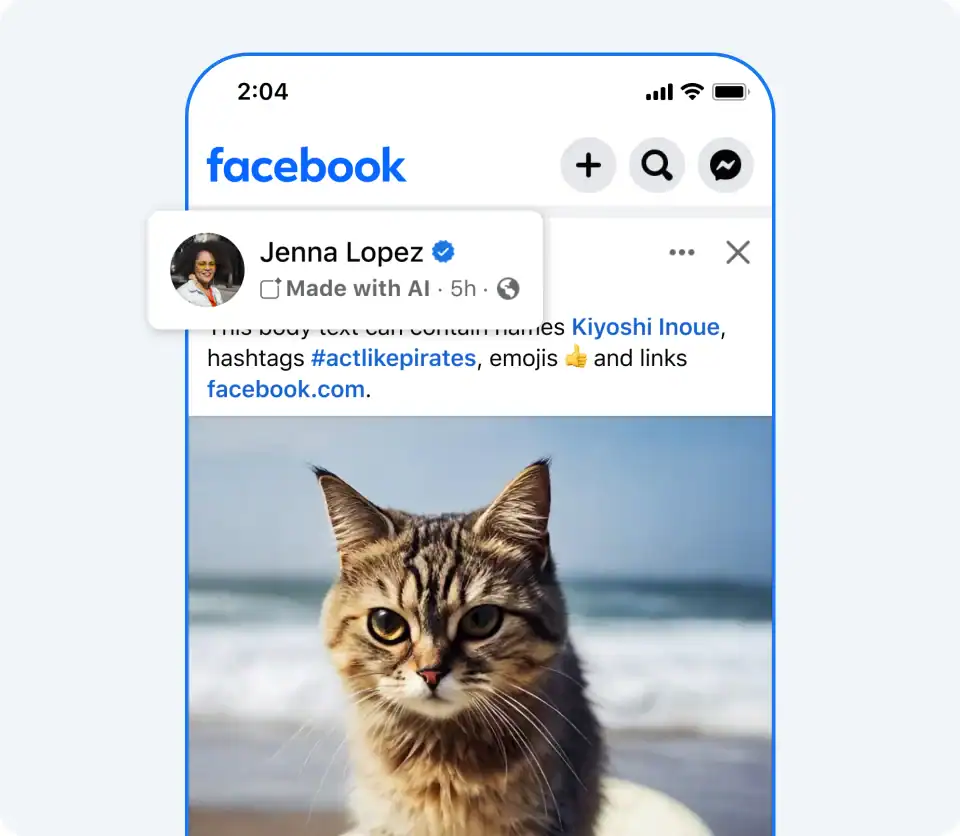
In other words, provenance matters not for purity, that is, free of AI, but for credibility.
This ambiguity has real consequences for creators. When even minor edits risk triggering an AI-generated label, artists and professionals are trapped between two failures of recognition: either their human authorship is erased, or their work is dismissed as synthetic without cause.
But the impact doesn’t stop with the creator. For viewers, the ability to trust what they see begins to fracture. If AI was involved, is the image still believable? Still trustworthy? Or is it an illusion, something closer to hallucination than documentation?
The more the boundary blurs, the more credibility erodes, not just in the image, but in the systems presenting it. And beyond, society itself.
Newsrooms: Walking Away from Tools They No Longer Trust
Nowhere is this erosion of clarity more dangerous than in journalism. Newsrooms aren’t abandoning Photoshop because of its flashy generative features, but because they no longer know how much AI takes over during routine edits. When a photographer or editor crops an image or adjusts the exposure, they can’t tell to what extent the software is making decisions on their behalf, information Adobe has yet to make transparent.
And the concern is spreading. In some newsrooms, editors are also beginning to question whether smartphone photos can be considered “real” at all. Phones routinely enhance skin, replace skies, even fuse multiple exposures, sometimes swapping faces for a more aesthetically pleasing expression, without any user command. These computational interventions may improve aesthetics, but they also obscure authorship and subtly alter the factual record. If an image is composed of algorithmic reconstruction, did it capture something that really happened? Can it still be trusted as a faithful document of reality? and if it’s so AI affected, who owns the copyright, if anyone?
In journalism, the answer must be clear. If the provenance of an image cannot be traced, and if the editorial team cannot confidently say what is real and what is altered, then the image may not be publishable, regardless of its visual appeal.
Who owns the final image in this video? And can it still be considered a photo or an AI-generated output? credit Heath Waugh / Matterstudio.ai
The Law, Still Catching Up
Copyright law, for its part, draws a hard line: works created by AI are not protected unless a human can claim creative authorship. But in visual content, authorship has traditionally been expressed through dozens of small, intentional choices, many of which are now executed automatically by software. These are no longer decisions made by the creator, but actions triggered by tools whose influence is often opaque. A small edit can dramatically alter meaning. A minor addition can void protection.
The Meta study acknowledges this complexity:
“Defining materiality is challenging… even minor edits can significantly affect the content’s meaning, depending on the context.”
While early interpretations were rigid, recent guidance from the U.S. Copyright Office has introduced more nuance. It now recognizes that works combining human and AI-generated content may qualify for protection, but only for the portions attributable to human authorship. The Office requires a clear disclosure of what the human contributed, and will deny protection to parts created solely by AI.
But even this framework is hard to apply in practice. Still, where is the line drawn exactly? When AI is embedded deeply in editing tools or content pipelines, the boundaries of authorship blur. Creators may not know where their input ends and the machine’s begins. Until courts and platforms can operationalize this partial authorship model, both enforcement and protection remain precarious.

What is it hiding?
The real issue isn’t just how much AI is being used, or where, it’s what that use is concealing. At the heart of it is intent. Is the image meant to mislead or to inform? To manipulate or to reflect?
An artist’s intent is to deceive, but in a way we understand and accept. The illusion is purposeful, even celebrated, because it’s aimed at deeper truths. We enter that relationship knowingly.
But photojournalists, scientists, documentary filmmakers, teachers, and law enforcement work under a different contract: to replicate reality as faithfully as possible. Here, any deception is a violation of trust. And we take that fidelity for granted, until it breaks.
Most of us, and most brands, fall somewhere in between. We don’t always mean to deceive, but we take liberties with reality. We want to impress, persuade, and stylize. And in doing so, we blur the line.
That’s why knowing how much editing was done, where, and how, especially when AI is involved, matters. It gives viewers a chance to interpret intent, to decide whether to extend their trust or withhold it.
Why This Needs to Be Solved, Now
The longer we delay defining what qualifies as AI-generated -what exactly are the limits- the more confused the ecosystem becomes. Platforms are developing labeling systems without shared thresholds. Legislators are proposing rules without workable definitions. Creators are being marked as synthetic. And viewers are being left to decide for themselves what to trust, without a clearly defined boundary, each platform having its own. What is labeled as AI in one place might not be in another.
There is no lack of technology to track provenance. Watermarking, metadata, and edit logs are improving fast. But they are meaningless without agreement on what they’re supposed to prove.
What we lack is a standard. A shared, enforceable understanding of what separates human authorship from machine fabrication, not just for courts, but for platforms, creators, and the public.
The Meta report ends on a telling note:
“We need continued research to improve robustness… and research-backed definitions of materiality which are operationalizable at scale and reflect user and policymaker expectations.”
Until we have those definitions, all transparency efforts will be noise.
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”