
….The Real Story Is What Comes Next.
On February 10, India issued a rule requiring all media platforms to clearly identify AI-generated content. The deadline: February 20. That gives every platform operating in the country, Instagram, Facebook, YouTube, WhatsApp, X, and the rest, ten days to comply.
As of today, that’s 3 days left.
The rule, published by the Ministry of Electronics and Information Technology — India’s central government ministry responsible for IT policy, digital governance, and internet regulation (MeitY) as Gazette Notification G.S.R. 120(E), amends India’s IT Intermediary Rules to bring what it calls “synthetically generated information” under formal regulation for the first time. The definition is broad: any audio, visual, or audiovisual content that has been artificially created, generated, modified, or altered using AI in a way that makes it appear authentic. Not just deepfakes. Any AI-generated or AI-manipulated content.
What the Rules Actually Require
The obligations go well beyond slapping a label on things. Every platform must prominently label AI-generated content and embed permanent metadata or provenance markers, including a unique identifier traceable to the tool that created it. Once applied, those labels and that metadata cannot be removed, suppressed, or modified by anyone. That last part is key: it means platforms can no longer strip provenance information from uploaded images, which is exactly what most of them do today.
Larger platforms face even stricter requirements. Significant Social Media Intermediaries (SSMI) – defined as platforms with five million or more registered users — must require users to declare whether their content is synthetically generated before it goes live, and then deploy automated tools to verify those declarations. If the declaration or verification confirms synthetic content, the platform must ensure it is clearly labeled.
The enforcement teeth are real. Takedown windows for unlawful content have been cut from 36 hours to three. Platforms that knowingly allow unlawful synthetic content lose their safe harbor protection under the IT Act, they become directly liable. MeitY’s FAQ clarifies that routine editing, such as cropping, color correction, or adding subtitles, doesn’t count, nor does good-faith educational content. But everything else is in scope.

And the scope is massive: roughly 481 million Instagram users, 403 million Facebook users, over 500 million YouTube users, and more than 535 million WhatsApp users. India is the world’s largest market for WhatsApp, the second-largest for Instagram and YouTube. When India tells platforms to change how they handle content, the platforms listen.
Three Blocs, One Direction
India is not acting in isolation. What makes this moment significant is the convergence of three regulatory frameworks arriving at remarkably similar demands.
China moved first. The Cyberspace Administration’s Measures for Labeling AI-Generated Content took effect on September 1, 2025. China’s requirements are the most prescriptive: visible watermarks, invisible watermarks in the pixel data, including the service provider’s identity, and metadata embedded in saved files. App stores must verify labeling functions before listing AI applications.
The EU took the broadest approach. The AI Act’s Article 50 requires AI-generated content be marked in a machine-readable format. While the Digital Omnibus Act has pushed full enforcement to 2027–2028, the direction is set: mandatory, persistent, machine-readable provenance.
India sits squarely between the two. Like China, it demands visible labels and permanent metadata. Like the EU, it frames the obligation in terms of platform accountability rather than prescribing specific technologies. Its timeline is the most aggressive: ten days.
Combined, these three frameworks cover more than four billion people. Any AI company or platform operating globally must now answer the same question from three directions: can you prove your AI-generated content is labeled, traceable, and preserved through distribution?
Why Metadata Is the Only Path That Works in Ten Days
The ten-day window is a forcing function. No platform can build new detection systems or deploy novel watermarking infrastructure in ten days. What they can do is stop destroying the metadata that already exists.
Many major AI generators already embed provenance information in their outputs, through C2PA Content Credentials, IPTC Digital Source Type labels, invisible watermarks, or some combination. The information exists at the point of creation. The problem has never been generation. It has been implementation: platforms routinely strip metadata from uploaded images for performance, storage, and privacy. India’s rule, by explicitly prohibiting the removal of AI labels and metadata, directly targets this practice.
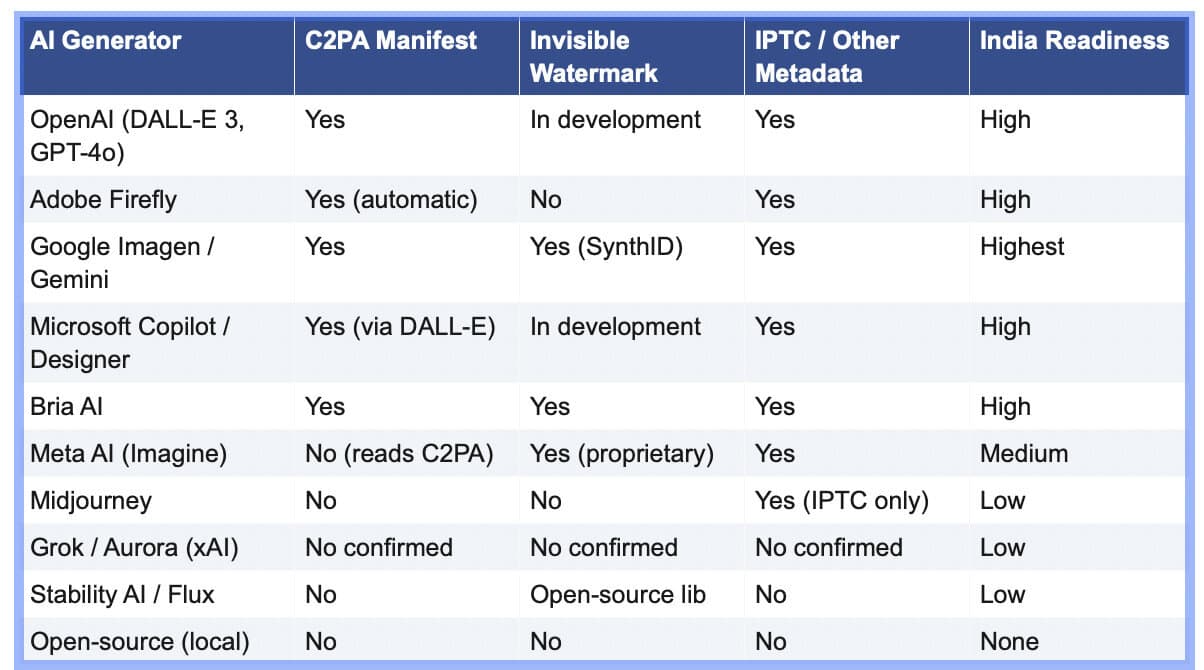
Google’s dual-layer approach, SynthID watermarks in the pixels plus C2PA and IPTC in the metadata, is the most robust stack available. Adobe Firefly and OpenAI provide strong coverage through automatic C2PA and IPTC embedding. Bria AI covers the full stack for enterprise API customers. At the other end, Grok has no confirmed provenance implementation, and open-source models running locally embed nothing at all, the largest structural gap in the ecosystem.
Why This Won’t Stay in India
When Meta must preserve AI metadata for 535 million WhatsApp users and 481 million Instagram users in India, it faces an architecture decision: geo-specific metadata handling, or a global policy change. History suggests the latter. When GDPR took effect in 2018, most companies implemented its requirements globally rather than building Europe-only systems. The cost of parallel processing pipelines exceeded the cost of applying the stricter standard everywhere.
The same logic applies with even greater force. China already requires metadata preservation. India now requires it. The EU will require it. California’s AB 853, effective August 2026 as well. At some point, building separate handling for each jurisdiction becomes more expensive than simply preserving provenance globally. We are already past that point.
The compliance obligation also cascades through the content supply chain. Photo editors with AI features, design platforms with generative tools, marketing software with AI image generation, e-commerce platforms, CMS systems, DAM workflows, and any software embedding an AI generator through API integration must consider whether its outputs carry proper provenance markers. Companies that preserve provenance through their pipeline gain a compliance advantage. Those who break it become liabilities for their customers.
The Content Credentials Paradox
This regulatory convergence forces an uncomfortable question: what happens to Content Credentials if the only content that carries them is AI-generated?
C2PA was designed to be universal, with cameras, editing software, news organizations, and AI generators all embedding provenance, creating a trust layer for all digital media. Leica, Nikon, and Sony have started implementing it. Adobe embeds credentials across Creative Cloud. The BBC and the New York Times have explored it for journalism.
But regulation is accelerating AI labeling far faster than organic adoption is spreading credentials to everything else. If Content Credentials become mandatory for AI-generated content while human-created content remains largely unlabeled, credentials risk becoming synonymous with one thing: ‘this was made by AI’. That creates a perverse incentive. Photographers and publishers may actively avoid them, not because they oppose transparency, but because they don’t want their work mistaken for synthetic content by audiences who have learned to read credentials as an AI marker.
The alternative requires faster action. If cameras, news agencies, stock platforms, and social networks adopt credentials broadly enough that they signal “verified provenance” rather than “AI-generated,” the regulatory mandates become a tide that lifts all boats. But that window is closing. India’s mandate, China’s enforcement, and the EU’s approaching deadlines are accelerating the AI association on a timeline measured in months.
What Happens Next
February 20 is the compliance date. Enforcement will matter: India has been aggressive about IT rules compliance, and MeitY is unlikely to accept technical difficulties as an excuse. The open-source gap remains unsolved: models running locally produce images with no provenance, forcing platforms to rely on imperfect detection and user self-declaration. Any content with poor or no labels will become toxic. When social media platforms cannot identify the source, their default action will be to reject it to avoid liability.
But the deeper story here is not about any single regulation. It is about metadata.
For most of the digital era, metadata has been an afterthought, something routinely stripped, ignored, or treated as a storage optimization problem.
That era is ending. Three of the world’s most consequential regulatory regimes have independently concluded that metadata is not overhead. It is infrastructure. India’s mandate, China’s enforcement, and the EU’s and California’s approaching deadlines are thrusting metadata from the sidelines into a predominant role: the mechanism through which trust, authenticity, and legal compliance will accompany every piece of content.
This will force everyone — platforms, publishers, creators, software companies — to revisit what their files carry when shared publicly. Which fields survive upload? Which provenance signals persist through editing? Whether a file’s history is preserved or destroyed in transit. These questions, invisible to most users for decades, are suddenly at the center of global compliance.
For better or worse, metadata has just become the most important part of every image file. And the industry now has 2 days to start acting like it.
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”