
….. if they understood what they actually have
For two decades, photo agencies have been selling pixels. The price of those pixels has been falling for almost as long, and generative AI has now removed the floor entirely. The conversation inside the industry has narrowed to a single question: how do we keep selling pixels in a market where pixels are free?
This is the wrong question. It assumes the agency’s product is the image. It is not, and it has not been for some time. The agency’s product is the verified context around the image: who took it, where, when, under what conditions, with what claims to truthfulness, and with what rights attached. The pixels are the carrier. The carrier is no longer scarce. The context is.
A small publishing company in California has just demonstrated, with real revenue and real authors getting paid, what selling context looks like in the AI era. It is worth understanding what they built, because the model they have proven for books is dramatically more interesting when applied to photographs.
What O’Reilly figured out
O’Reilly Media has spent the last several years building something called O’Reilly Answers, a system that answers technical questions using the company’s own library of books. A developer debugging a Kubernetes problem at two in the morning asks a question inside their code editor, and gets an answer drawn from O’Reilly’s catalog, with citations down to the paragraph and a link back to the source chapter.
The system runs on open-source models fine-tuned to retrieve content from O’Reilly, not trained on it. Every answer carries a forensic attribution trail, which book, which chapter, which paragraph contributed how much to the response. Because the attribution is precise, royalties flow to authors based on actual use of their work, paid per interaction rather than per file sold. According to O’Reilly’s own statements, the system serves 2.5 million paying subscribers and is “really lucrative” for the publisher and its authors.
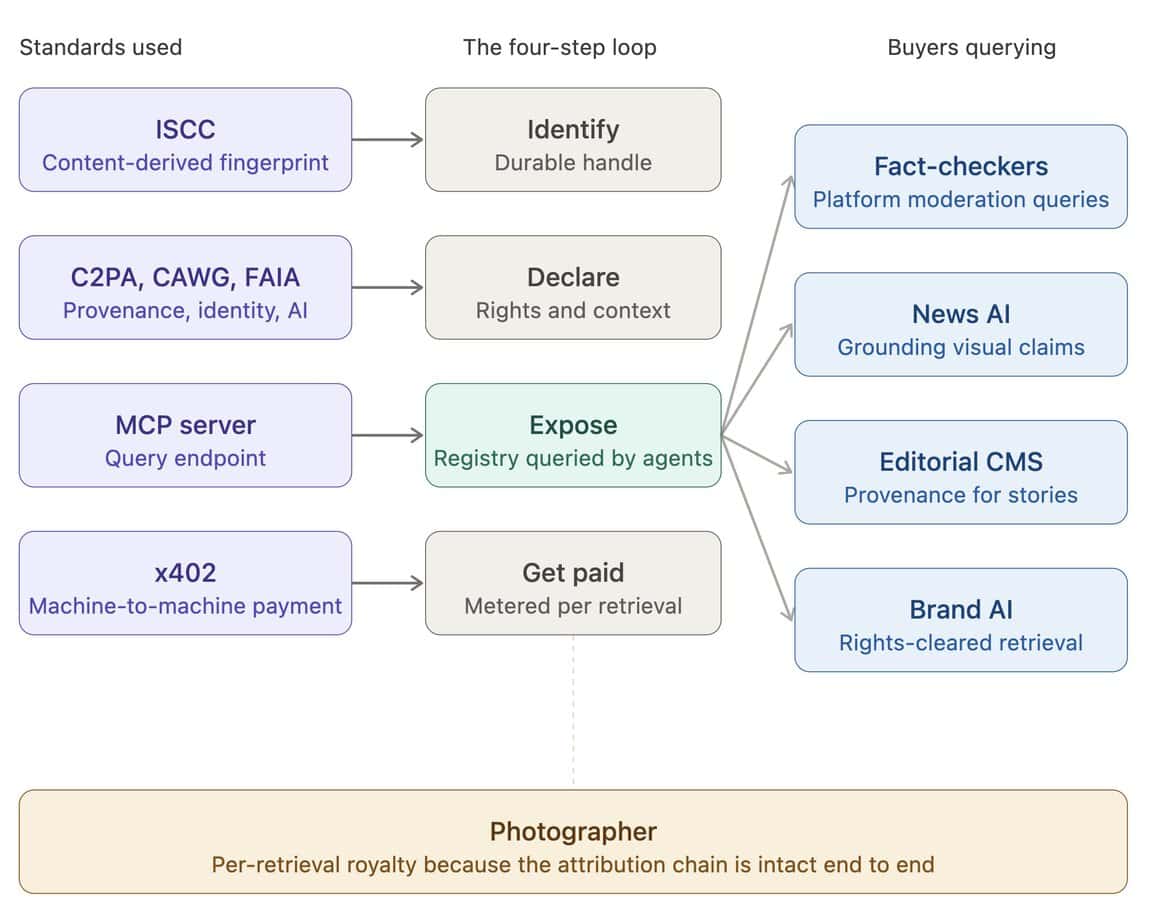
What O’Reilly proved is a four-step loop that works:
- Identify the content with a durable handle.
- Declare what it is, who made it, and what the terms are, in a way machines can read.
- Expose it to AI agents through a structured access point (in their case, an MCP server — Model Context Protocol, the emerging standard for letting AI tools query external knowledge).
- Get paid when an agent retrieves it, with the value flowing back to the original creator.
This is the doorway. What is on the other side of it, for a photo agency, is more valuable than what O’Reilly itself has built.
The thing photo agencies have that text publishers do not
A book is a synthesis. A model can paraphrase it, summarize it, recombine its arguments with arguments from ten other books, and erase the trail. The author can demand royalties for the use of the original, but a sufficiently transformed response is, by design and by training, objective, no longer recognizably the book.
A photograph is not a synthesis. A photograph is testimony. It is the trace of light from a specific place at a specific moment, captured by a specific person who was there. A model can generate something that looks like a photograph, but it cannot generate the testimony, because the testimony is the link between the pixel and the event, and that link can only be made by someone who was present.
This is the asymmetry that matters. AI can compete with text publishers on synthesis. AI cannot compete with photographers in terms of presence. What an AI system needs, when it is asked to ground a claim about the visible world, is exactly what photo agencies have always trafficked in: a verified chain back to a moment that actually happened.
The product that follows from this is not stock licensing. It is verification as a service, and it is something only an agency with a real photojournalism backbone and a real chain of custody can sell.
The four layers, applied
The same four-step loop O’Reilly built for books works for photographs, but the layers carry more weight.
Identify. Every image in the archive carries a content-derived fingerprint (ISCC — International Standard Content Code, an ISO standard for identifying media by computing a hash from the file itself rather than embedding one). Because the identifier is derived from the content, it survives re-encoding, cropping, format conversion, and screenshotting. An image found anywhere on the open web can be hashed and matched back against the registry. This is the durable handle that all the other layers attach to.
Declare. This is where a photo agency has assets no book publisher has. The declaration bundle includes the photographer’s verified identity (anchored in CAWG, the Creator Assertions Working Group‘s specification, which binds a cryptographic credential to the human making the assertion and resolves the question of whether the named photographer is actually the one whose work the assertion describes), the capture time and location, the chain of custody from camera to archive, the editorial caption, the model releases, the rights and licensing terms, and a structured flag for AI involvement (FAIA — the Fair AI Attribution Framework, which distinguishes Human-Created, AI-Assisted, and AI-Generated content for regulatory and provenance purposes). For photojournalism, the declaration also includes C2PA Content Credentials (the cryptographic provenance manifest now being signed by some cameras at the moment of capture). The declaration is the actual product. The pixels are the receipt.
Expose. The agency runs a structured access point, call it an MCP server, in current terms, that lets AI agents and software clients query the archive. A fact-checker asks: Does a verified photograph matching this hash exist in your registry, and what is its provenance? A news AI asks: Do you have verified images of this event from this date range and location? An editorial CMS asks: give me the full provenance and rights bundle for this image so I can drop it into a story. A brand-side AI asks: find me licensable images matching this brief, with rights cleared for this use case. One registry, four read patterns, four buyer types.
Get paid. Retrieval is metered. A fact-check query is cheap; a full editorial bundle costs more; a commercial license is full price. Payment happens automatically, protocols like x402 (a micropayment standard, designed for machine-to-machine commerce in fractions of a cent) handle the plumbing. Royalty flows back to the photographer because the attribution chain is intact end-to-end. Training the photographer’s work into a foundation model remains off-limits unless separately licensed; that is what the FAIA opt-out declaration enforces, and what downstream detection partners exist to police.
Why the economics are different from stock
Stock photography is a volume business with declining unit prices. The market clears at the level of “any image that fits the brief,” which is exactly the level at which generative models compete.
Verification is also a volume business, but structured differently from stock. Stock volume is humans browsing and licensing one image at a time. Verification volume is automated systems querying continuously at machine speed. A social media platform that fingerprints every uploaded image and queries the registry before the image is shown to anyone is running millions of queries a day. A search engine indexing provenance as part of its crawl is running the same query pattern at web scale. An insurance pipeline processing claims is running it continuously against the stream. They are asking a single structured question against everything that passes through them, automatically, on cycles that do not pause, millions of times.
The demand is not optional. Platforms will end up paying for verification because not paying becomes more expensive than paying. Regulators are tightening disclosure obligations on AI-touched and AI-generated content. Competitors that catch fakes a platform misses will use the gap against it. Once those pressures converge, the cost of being the platform that ran the wrong image is higher than the cost of running the queries.
There is also no substitute. A news AI that needs to cite a photograph as evidence of an event cannot use a generated image; the generated image is the opposite of what the citation requires. A fact-checker cannot use a generated image to answer a question about whether an image is generated. For the uses verification is built for, an alternative does not exist.
This is a demand that did not exist five years ago, and that grows mechanically with every increment of generative capability. The more capable the models become at producing convincing fakes, the more valuable a verified chain of custody becomes. The agency that owns the verified chain is positioned on the right side of that curve.
The royalty question follows. Photographers have been told for a decade that their unit economics are collapsing, and they have been told correctly. What has been missing is a model in which value accrues to the photographer in proportion to the use of their work after the initial sale. A per-retrieval royalty on verification queries, paid each time someone needs to confirm that a photograph the photographer took is genuinely a photograph the photographer took, is exactly that model. It is the first plausible answer in years to the question of how the witness gets paid for being a witness.
What this means for agencies
The agencies that can build this are the agencies that already have the inputs: a roster of photographers with verifiable identities, a controlled ingestion pipeline, a culture that takes captioning and metadata seriously, a customer base that already cares about provenance. That description fits the news-DNA agencies (the DPAs, the IMAGOs, Reuters, Getty Images, the editorial-first players) far better than it fits the stock-scale platforms whose unit economics depend on volume rather than verification.
The decisions an agency needs to make are not primarily technical. The standards exist (ISCC is ISO 24138, C2PA is moving through ISO, CAWG and FAIA are in working draft, MCP is published, x402 is live). The protocols are interoperable. What an agency needs to decide is:
- Whether it wants to be in the verification business at all, or wants to keep selling pixels until the pixel market closes.
- Whether it is willing to invest in the declaration layer, the captioning, the chain of custody, the photographer identity verification, at the level of rigor that machine-readable trust requires.
- Whether it can move quickly enough to seed the registry with enough coverage to be useful, while the AI agents that will buy from it are still being built.
- Whether it will cooperate with other agencies on a federated registry model (the way Europeana, Wikimedia Sverige, and others are already doing through CommonsDB), or insist on a proprietary silo and lose the network effect.
The last of these is the one that determines whether verification becomes a product or a category. A single agency selling verification is a niche service. A federation of agencies running compatible registries on shared standards is the answer layer for visual reality in the AI age , the layer every news AI, fact-checker, CMS, and brand agent will route through by default because nothing else exists that can answer the question.
The clock
The window for this is narrow and is not opening on the agencies’ schedule. The AI assistants that will become the dominant retrieval surface for the next decade are being plumbed now. The standards bodies are setting defaults now. The protocols for machine-to-machine commerce are being deployed now. An agency that is in the registry when those defaults are set is the agency that gets queried. An agency that joins three years later joins a market with established incumbents and standardized prices.
Photo agencies have spent a long time trying to defend the pixel business. The verification business is here, and it is, for once, a business that plays to exactly the strengths that photo agencies were built on: chain of custody, captioning rigor, photographer relationships, and editorial trust.
The question is no longer how to survive the AI-mediated information economy. The question is whether the agency wants to be a part of that economy that everything else has to call to check its facts.
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”