
Making sense of the trillions of images now available on-line can reveal fascinating information about our society. Taking the first steps in this complex field that mixes art, computer science and sociology, Dr Lev Manovich, professor at the Graduate Center of the City University of New York explains, via a few of his projects, how we can learn by just looking at what others are capturing. This is the transcript of his 2015 LDV Vision Summit presentation:

We all hear this expression “thinking outside of the box.” For me, the box is this one [holds up smartphone], which enables amazing experiences and changes the world, but it’s also very limiting as a mechanism for visual experiences.
I was a professor of visual arts at the University of California, San Diego, and we opened a new research center called California Institute for Telecommunication and Information (Calit2) which brought together some leading researchers building new platforms for information visualization, such as this one, which consists of dozens of flat screens:

When I saw it in 2005, exactly 10 years ago, I had this “aha” moment and I imagined: What if I could take all digitized Renaissance paintings from, let’s say, 1500 to 1600 in Italy, and put them on this wall, and use computer vision to sort them by color, content, composition, and actually have a better understanding of what the Renaissance was? This was even before social media exploded.
For the last seven or eight years, me and my collaborators worked on such projects in our research lab. Now it operates between the University of California-San Diego and here at the Graduate Center at CUNY, where I am teaching since 2013. Meanwhile, I also made the transition from being a professor of art for 20 years. Six years ago I started learning Excel, then R, and now I’m professor of computer science teaching PhD-level computer science students data analysis and art. Just one step away from my students. We developed further this idea of looking at large image collections and using visualization techniques, and also using computer vision to understand various cultural datasets. I’ll show you a selection of five projects. Three of them will be using contemporary user-generated content, such as Instagram, but before that, I will show you a couple of projects where we look at collections of digitized historical imagery.
Two years ago, we were invited by the Museum of [Modern] Art in New York to look at their whole photo collection. Of course, they have everybody who’s anybody from the 1840s until today, but nobody has ever visualized the collection as a whole. So here we applied the most simple 200-year-old technique of bar graph.

It’s a bar graph which shows all the images of the photo collections, about 20,000, but it’s a bar graph which is made from all individual photographs in the collection. When you zoom in, you can start to look at the whole collection in a single image. You realize that it’s a very particular representation of the history of photography.

It’s all about the great people, but not only about these great people. It’s about the people which MoMA deems important. For example, from 1920s to 1930s, you have lots of modernist abstract photography and you don’t have lots of photojournalism. When you look at this photo collection as a whole, you can also see that MoMA is very strong in 1920s and 1930s. That’s why you have this big spike. There was a little bit of a spike in 1970, but other decades are not represented very strongly.
Now I will show you another project we have done in the lab: analysis and visualization of one million manga pages. I said: “I’m interested in visual style of manga.” Manga is one of the most popular cultural forms today and it includes Japanese, Chinese, French, etc. comics but it started in Japan. The pages are sorted by one dimension of visual style. On the one end of this dimension are the pages where you don’t see lots of detail, not lots of texture, image are all black and white images.

On the opposite end, we have opposite style—lots of texture, 3D, lots of labor. Using the very basic techniques of computer vision, we measured some visual features such as entropy, and standard deviation and so on. Then, using a little visualization tool which I wrote (I’m very proud of it, because it turns out there was no actual tool to visualize lots of images together), we simply sorted all those images.

That was done in 2009. It took about two days to render, and now it would take a few hours. Here are one million manga pages, which correspond to the most popular manga titles around the world, organized by two visual features:

As you already saw, the feature which organizes images on the vertical axis is entropy. We get images of very high entropy, lots of detail on the top of the cloud while images with very low entropy and opposite at the bottom. It’s like discovering a new continent. To use a metaphor, it’s like people coming to America 500 years ago and discovering this new continent and mapping it out. What is the map of this continent called manga? What is the most popular manga being created? What manga people did not create? If I’m a young artist and I want to make something original, I should operate in the lower right corner, or maybe the upper left corner, because for whatever historical, cultural, evolution reasons, there has been much manga created in this style. It’s kind of diagnostic; it’s like an x-ray of a cultural field.
Now I’ll show you briefly three projects we’ve done in the last few years where we applied these concepts to look at user-generated content—specifically using Instagram. For our first project done in 2013 ( it was called “Phototrails”), we simply started in a very broad way.
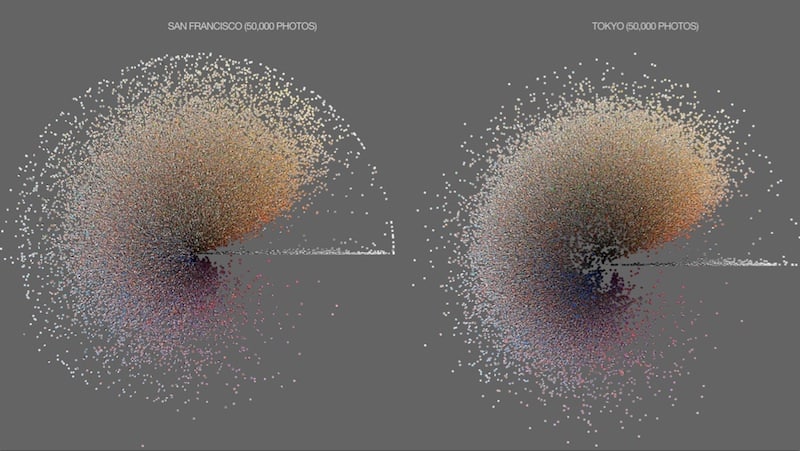
We downloaded 2.3 million Instagram images from 13 global cities, and then using very simple visual techniques and this idea of mapping big image samples together, we started to compare visual signatures of different cities. Here, for example, you have 50,000 images of San Francisco compared to 50,000 images from Tokyo organized by image brightness and average hue. And we can also organize images by time:
Here, for example, you have one week in Tel Aviv. The images are organized by hue and by time and day of the week, so you get these little slices which correspond to each day and you see these visual routines:

Even when people are taking very different images for very different purposes, almost every day looks the same. But you have a couple of days at the bottom where something exceptional is taking place. In fact, these are the two most important national celebrations in Israel, and you see something happened. But you also see reflections of some exceptional events are just like a weak signal, let’s say, in the sea of, I wouldn’t call it noise, but in the sea of everyday visual routines.
This is a close-up of the same image so you can see that it’s all made from individual photographs:

This is a little bit closer to home. This is 24 hours on Instagram of publicly shared images in Brooklyn, which we also downloaded during an event which took place a couple of years ago, Hurricane Sandy:
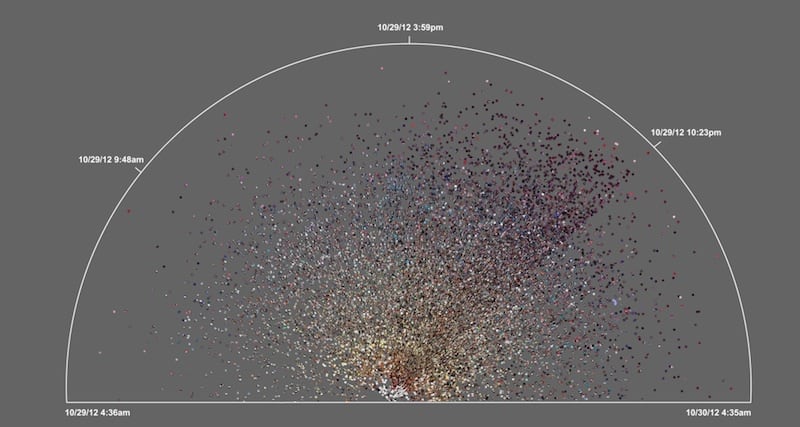
So the time goes clockwise—the images were organized by time and simply by average hue. And you know what happened at 10:23 pm on October 29 where Con Edison Station went out of service, and a big part of NYC suddenly went dark. You see how much these kinds of dramatic events are immediately reflected both in the quantity and the different kinds of images being shared.
In the fall of 2013, we said: “Now let’s make a new project.” As opposed to comparing images from different cities which is a bit like comparing apples to oranges, we said: “Let’s compare images of a particular kind: selfies.” We started to work this a few months before the selfie became very famous. We decided to download thousands of selfies from around the world and use various visual techniques and a bit of computer vision to compare them.
The key part of the project is this interactive, web-based interface, which we call “Selfiecity,” where you can navigate a database of 3200 selfies from five global cities using various metadata.
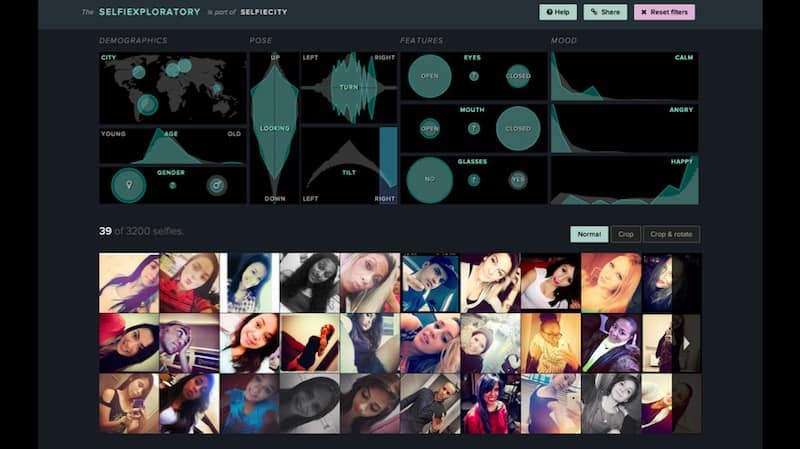
Interface is, in fact the key purpose of our research. We don’t want to reduce the variety or the richness of the visual world to bar charts and pie charts, right? We want to be able to combine media browsing with graphs because every image is not just a data point. An image is a whole visual universe. I think this problem of how we can actually do it, for example in the mobile device, hasn’t really been addressed yet.
So this is our latest project, On Broadway.
It’s a computer-driven installation which is installed for 13 months in New York Public Library on the 46-inch touch screen. Here we’re focusing on visualizing all of New York by using a street, which is Broadway, and combining about 40 million data points and images. The task is how to combine multiple layers of data and images into one interface. So we have everything from Google Street façades, façade images colors, information for 22 million taxi rides along Broadway last year, median income, Google Street View again, Instagram, and neighborhood names, etc.
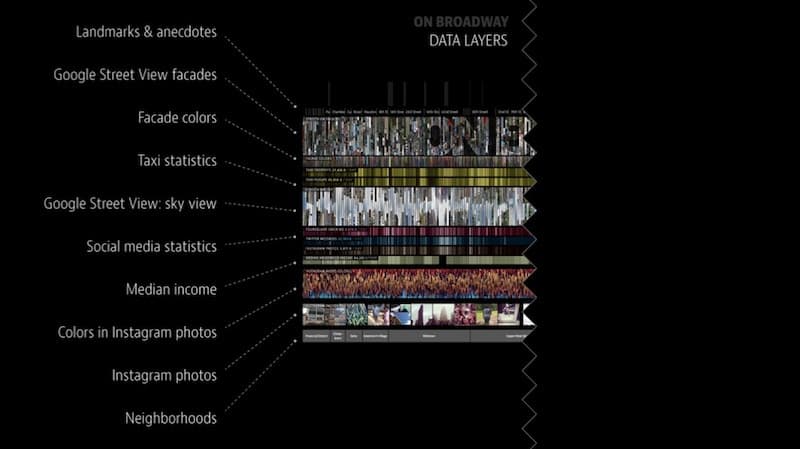
The idea is to create a kind of interface where you can navigate this, building by building, or you can zoom out using familiar touch gestures and go through the whole thing.
The idea is to downplay statistics and focus on images. Also, we wanted to explore the idea of: Can we create an interface for a city which doesn’t use a familiar map? So we don’t have a single map on the interface.

This is just a screen capture with video and you can interact yourself if you go to New York Public Library main building on 42nd street and Fifth Avenue (NDLR : it ended on January 3, 2016) . It shows navigation, so at any point you can also click the button and get selection of Instagram images at a particular point. You can also zoom out and see the whole city or you can zoom in and navigate the city one building at a time. It is a zoomable interface, which is our attempt to think about how we can put together urban data, potentially hundreds of thousands of layers of data, and present it to users in a visual interface.

You can purchase the full transcript of all the 2015 LDV Vision Summit panels:
[Kaptur is a proud media sponsor of the LDV Vision Summit]

Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”
1 Comment