
For years, we’ve been told that data is the new oil, and in the world of artificial intelligence, that metaphor feels almost understated. Every major AI breakthrough, from large language models to image synthesis engines, rests on vast amounts of labeled, real-world data. But unlike oil, data isn’t something you drill for. It’s something you take, often without asking.
At the center of this uneasy economy lies the licensing market for training datasets, serving as the bridge between those who own content and those building AI systems that mimic, manipulate, and monetize it. It should be a booming, well-structured ecosystem. And to some extent, it is. But for many content owners, especially those working with visual material, the rewards remain elusive, and the rules are still being written.
The Market: Growing Fast, Trading Quietly
According to research by MarketsandMarkets, the global market for AI training datasets is projected to grow from $2.68 billion in 2024 to $11.16 billion by 2030, a compound annual growth rate of over 22%.
Yet the size of the market tells only part of the story. Much of this activity happens under NDA, without pricing transparency, and often with questionable sourcing. The line between what is licensed and what is scraped remains blurred, and, increasingly, contested.
What Gets Licensed, and Why It Matters
Text remains the bedrock of most AI models, and it’s no longer just scraped web text powering these systems. Over the past year, major publishing houses have stepped forward to license content directly for AI training, signaling a shift from ambiguity to transactional clarity.
Industry giants like News Corp (including The Wall Street Journal and New York Post), the Financial Times, Axel Springer, Le Monde, Prisa Media, Dotdash Meredith, and HarperCollins have inked deals with OpenAI and others. Payment structures vary—upfront fees, ongoing subscriptions, and usage-based royalties, often falling in the $1 million–$5 million per year range for legacy and current archives.
And it’s not just news media: scholarly publishers, including Taylor & Francis, Wiley, Cambridge University Press, and Oxford University Press, have signed LLM licensing agreements, reflecting a recognition that their archival and academic content holds significant AI training value.
Despite this emerging monetization trend, the bulk of training data still comes from public domain or scraped text, Wikipedia, Reddit, Common Crawl, and the notorious Books3 corpus. Deals initiated by The New York Times and others have challenged this status quo, but so far only a minority of content is licensed. The rest floats in a shadow economy, quasi-legal at best.
Audio data, particularly human speech, has growing value in domains like voice cloning, multilingual assistants, and call center automation. Commercial datasets are typically priced by volume and language coverage. For example, providers like Nexdata offer large-scale speech corpora (5,000+ hours) at rates starting around $20,000, which translates to approximately $0.07 per minute for high-quality audio.
Other vendors, like Defined.ai, provide similar multilingual bundles, with cost varying based on speaker diversity, transcription quality, and intended use. Though exact figures are often under NDA, price-per-minute rates generally remain in the low-dollar range for structured, labeled audio, especially when bundled in bulk.
By contrast, open-access datasets such as Mozilla Common Voice or VoxPopuli are freely available but may lack the demographic specificity, licensing clarity, or metadata granularity required for enterprise-grade AI training.
Video is a newer but increasingly critical input for multimodal and robotics models. Companies are now paying creators for their unused footage. As Bloomberg reports, AI companies are offering $1–$2 per minute for regular content and up to $4 per minute for premium formats like 4K drone or 3D video.
3D and sensor data, often collected from LIDAR, AR/VR platforms, or robotics labs, commands some of the highest licensing fees, often in the six-figure range, because of its scarcity, technical complexity, and proprietary nature.
Visual content sits in a more precarious space. It is critical for training AI models that “see” the world. It is also among the most legally protected and difficult to license at scale.
Visual Content: Essential, Vulnerable, and Weaponized
Photography and videos are not just representational media, they’re documentation of the world as it exists. That makes them uniquely valuable for machine learning models, especially in sectors like surveillance, e-commerce, healthcare, and autonomous vehicles. But it also makes them a target.
Bulk photo dataset licensing rates from providers like DatasetShop can range between $0.01 and $0.25 per image, depending on resolution, subject matter, and exclusivity.
Stock agencies themselves are now disclosing the growing financial importance of AI training data:
Shutterstock reported approximately $104 million in revenue during 2023 from licensing digital assets to AI developers—and expects that figure to rise to around $250 million by 2027.
Getty Images, in its Q4 2024 filings, attributed ongoing subscriber growth and content licensing strength to AI-focused initiatives. While it hasn’t broken out a specific number, its sustained revenue uplift and ongoing legal positioning confirm AI licensing as a core strategy.
Dividing the $104 million in 2023 AI licensing revenue by the 771 million images in Shutterstock archive suggests an average return of $0.135 per image. If only half the library was included in licensing deals, a plausible assumption given usage limits and training scope, the effective per-image value climbs to roughly $0.27.
That aligns neatly with the rates cited by dataset vendors and suggests that, at scale, low individual value can yield high returns at scale. While the precise pricing terms in deals with OpenAI, Meta, or other clients remain confidential, the public disclosures by Shutterstock and Getty Images validate the existence of a robust, rapidly expanding visual data licensing economy.
In short: this is no longer a speculative sideline for some. AI dataset licensing is becoming a core monetization strategy for content archives with large pool of content. However, for smaller ones with less than a million images, this is far from being a gold mine.
Regulation: The Slow-Moving Wildcard
For years, generative AI operated in a legal fog, training on massive amounts of data without clearly defined boundaries or permissions. That era is ending.
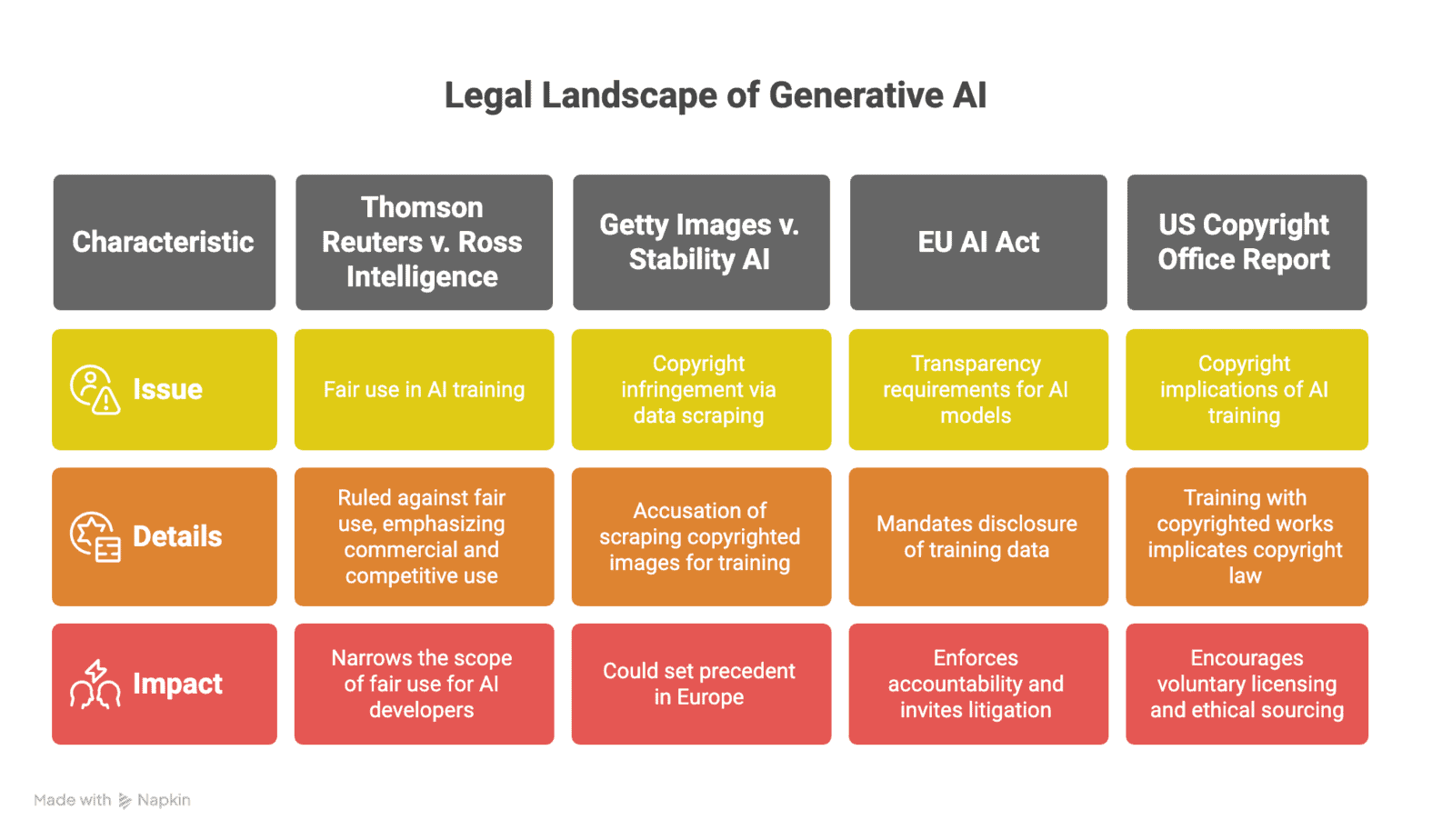
In March 2025, a U.S. federal court handed down a landmark decision in Thomson Reuters v. Ross Intelligence, ruling that Ross’s use of Reuters’ legal content to train its legal AI tools did not constitute fair use. The court emphasized that the use was commercial, directly competitive, and insufficiently transformative. The decision didn’t just reject fair use, it narrowed the terrain on which AI developers can rely on it going forward.
Another pivotal case is still unfolding. Getty Images’ lawsuit against Stability AI, currently being heard in the UK, accuses the company of scraping millions of Getty’s copyrighted images to train Stable Diffusion without consent or attribution. The outcome could become a benchmark on how visual content is handled, particularly significant given the simultaneous arrival of sweeping new regulations.
The European Union’s AI Act, effective since August 1, 2024, begins enforcing transparency requirements for general-purpose AI models in August 2025. These requirements compel developers to disclose the data used to train their systems. For companies that scraped content in the shadows, this changes everything. Transparency introduces accountability, and that invites litigation ( see above)
The U.S. Copyright Office, in its May 2025 report on AI training and copyright, reinforced that position. The Office concluded that using copyrighted works to train generative models does indeed implicate copyright law, and that “training is not inherently transformative,” especially when the outputs compete with the originals. While courts may still weigh fair use case-by-case, the report makes clear that copyright owners’ rights cannot be brushed aside simply because the data is used for machine learning.
Moreover, the Office strongly encourages voluntary licensing as the appropriate path forward and warns that compulsory or unlicensed use could erode the creative economy’s foundation. It explicitly rejects the notion that licensing would “throttle innovation,” noting instead that ethical sourcing is both feasible and necessary. As a reminder, the U.S. Copyright Office does not create law, it provides expert guidance and policy recommendations
Elsewhere, regulatory positions diverge:
Japan’s Copyright Act explicitly allows the ingestion and analysis of copyrighted works for AI training, even in commercial contexts, without requiring compensation or licensing, provided the output does not replicate the expressive content of the source. This makes Japan one of the most AI-welcoming major economies. However, critics, especially from the creative industries, worry this policy unfairly sidelines creators. That’s why the Japanese Copyright Office is considering whether to refine or narrow this exception.
China, in stark contrast, enforces rigorous regulation. Under the 2023 Interim Measures for Generative AI Services, application of copyrighted works for AI model training is permitted only when data is sourced lawfully, clearly documented, and does not infringe third-party IP. Additionally, operators require approval and licensing from the Cyberspace Administration of China before publicly deploying generative AI systems.
Providers must also conduct security assessments and adhere to data standards under the Data Security Law and PIPL, ensuring provenance and licensing compliance are enforced from source to deployment.
In the United Kingdom, initial proposals to exempt AI training from copyright were met with fierce resistance from rights holders. As of mid-2025, the government remains undecided, though parliamentary discussions increasingly point toward aligning with the EU’s transparency-focused model.
In short, the licensing economy for training data is no longer a theoretical battleground. The terrain is shifting, through legislation, through precedent, and through regulatory pressure. If transparency becomes enforceable, and fair use continues to narrow, AI developers will have little choice but to pay for what they consume. And for content owners, that marks the beginning of a very different conversation.
Synthetic Media: The Shortcut That Undermines Itself
To circumvent licensing constraints, some AI developers have increasingly turned to synthetic data, images, audio, or text generated by existing models and then recycled to train new ones. In theory, synthetic media offers a seductive solution: infinite volume, no copyright entanglements, and complete control over format and structure.
But this logic collapses under scrutiny. Multiple studies, including those cited by Google DeepMind and OpenAI, have confirmed that re-ingesting AI-generated content leads to “model collapse”—a compounding degradation of quality as models internalize their own statistical artifacts rather than sampling the real world. As each generation becomes further removed from authentic data distributions, the system’s outputs become brittle, repetitive, and less capable of generalizing.
To mitigate this, companies like OpenAI and Google are now building synthetic content detection systems, not only to label outputs for transparency, but crucially, to prevent models from accidentally retraining on their own outputs. The move signals an industry-wide acknowledgment: synthetic data, when fed back into the training loop, is not just suboptimal, it is structurally corrosive.
In the visual domain, the problem is particularly acute. Photographic training requires diversity, texture, environmental variation, and the unpredictable nuance of real-world capture. Synthetic imagery, however photorealistic on the surface, lacks the underlying distributional richness that models need to learn generalizable representations. As a result, reliance on synthetic inputs can lead to overfitting, hallucinations, and degraded performance in downstream tasks such as object detection, facial recognition, or scene understanding.
What began as a workaround to avoid licensing costs has become a technical liability. The more synthetic content is recycled into models, the further they drift from the truth they claim to understand. The shortcut, it turns out, leads not forward, but in a self-defeating loop.
What’s Next?
The licensing economy for training data is no longer speculative. It is real, growing, and under pressure. What was once an unregulated digital free-for-all is being slowly enclosed by courts, lawmakers, and commercial self-interest.
Visual content, in particular, stands at a crossroads. It is both indispensable and endangered, essential to AI’s understanding of the world, but easy to steal and difficult to trace. Whether creators and rights holders get compensated or bypassed will depend on what happens in the next 12 to 18 months: a convergence of lawsuits, legislation, and market restructuring.
For a full report, please click here (Free, access approval might be needed)
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”
3 Comments