
One of the lesser known application of data mining from images is satellite imagery. Mostly because it services businesses more than consumers. However, the combination of much larger pools of available images and advances in neural networks has made it one of the most promising and exciting field of visual tech. Second transcript from last year’s LDV Vision Summit, we give you Analyzing Satellite Imagery by James Crawford, Founder, Orbital Insight

I am James Crawford from Orbital Insight. our Company is based on—as many software companies are — a fundamental change in the hardware world. That fundamental change is expressed very nicely by this image. This is what satellites are going towards, where Planet Labs launches them 20 at a time. In the past, satellite imagery was interpreted by armies of people going back to the days of the Cuban Missile Crisis. And there are actually still thousands of people in Virginia whose job is to stare at satellite images every day. But as we start to fly not one but tens and eventually hundreds of satellites and UAVs, that doesn’t scale anymore, which is why we are here, why we are excited about machine vision, and why we founded the company.
We are interested in processing petabytes of satellite imagery and, more than that, determining what we can learn from them. The most a human can look at is about a million pixels but we have already run cases where we’ve analyzed 4 trillion pixels.
We can learn things about the world that we never knew before.
If you are a startup and you just got your seed round and you have to show customer traction right away in order to get more money, you start with hedge funds. The reason we did this is that they really want to know about the world and they are like race car drivers.
They want to be one-second faster than the next hedge fund. If you can tell them something they don’t already know about the world, they will pay you really soon. So we’ve had sale cycles of two days to get contracts signed with some of the hedge funds. In the longer term, there’s a ton of other applications that I am going to talk about.
One of the large projects that we’ve done is looking at US retail. Here we analyze a million parking lot images, which is about 4 trillion pixels, and we counted 700 million cars. This system is still running on a daily basis with imagery being uploaded from Digital Globe and Airbus and we are counting cars on an ongoing basis. We are now tracking 50 US retailers.
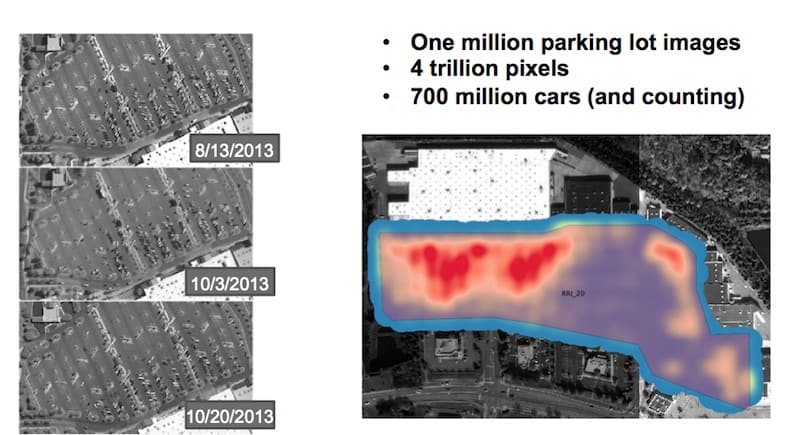
We can look at the data—700 million cars—in two different ways. One way is to look at a single parking lot. This is a heat map over six years of where people park. You can see they mostly park by the entrance doors. You can cut the image the other way longitudinally and look over time, and here you can see when people shop as a function of time.
This is Christmas, this is the summertime, and then if we zoom in on just Christmas you can see Black Friday and then the Saturday after Black Friday. All this comes out because we are working at scale. You wouldn’t get this if you were looking at a few parking lots, but because we are looking at literally a million parking lots we can pull out these sort of signals.
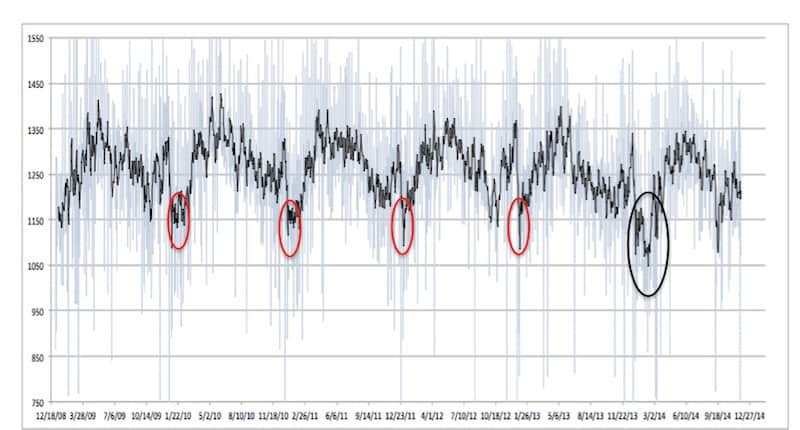
We found out the worst day to shop at Ross, of course, is Saturday, but also Wednesday is pretty popular. First, we thought this was a bug and then we realized they have a senior discount day on Wednesdays. All seniors are shopping on Wednesdays and that created the secondary peak. Since this is a machine vision conference, I wanted to show you just as much as I can in 10 minutes about how we actually do this.
This is done with deep learning. We had humans go through about 200 images and put little red dots on the cars. This is actually what the tiles look like. You can see at 50-centimeter resolution, the cars are not that obvious.
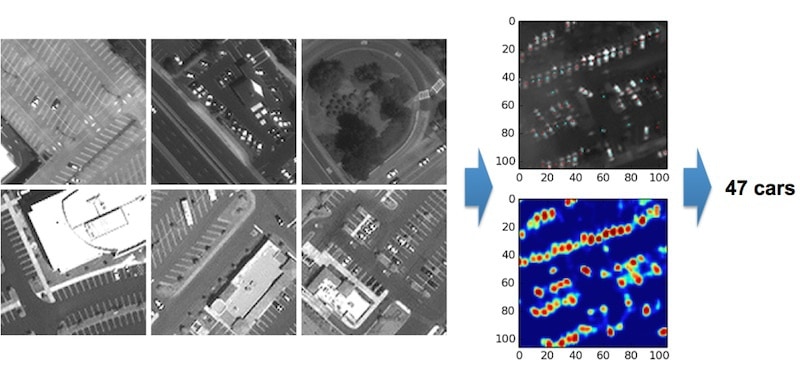
You can make them out but they are not plain as day. We had humans go through and mark them. And then the neural network uses a sliding tile to actually create a heat map of how likely each pixel is to be a car pixel. Then we take that heat map and turn it into a count. In this case, the result says there’s 47 cars in this parking lot.
Fortunately, since we are using so many images, we don’t have to be exactly precise on every image. We can tolerate single-digit errors in precision on single images and still be able to get these kinds of results—accurate results— at scale. From an investor point of view, a stock market investor, you also want to look at pairs trading. This is the kind of thing that really speaks to the guys a few miles north of here, who are actual traders.
You can see Home Depot versus Lowes, with Home Depot in the yellow and Lowes in the black.
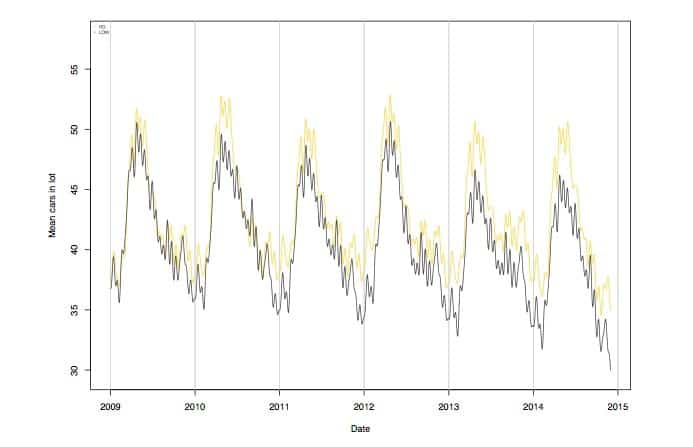
Back in 2009, they were almost neck and neck, but if you look in 2014, Home Depot was ahead almost every month of the year. Right after we put this chart together, Home Depot had their best quarter ever and the stock went up 5%. We didn’t predict that much of an extreme result, but we were more accurate in our predictions than the consensus of the Wall Street forecasters.
We also look at longer-term trends and we have tons and tons of slides on this, but I will just share one. If you remember the Polar Vortex of 2014, when basically winter failed to end. Usually, when we look over multiple years, there is a drought in January, but it’s pretty shallow in time. But this one was much broader. This is sort of the wisdom on Wall Street, that bad weather in the northeast depresses retail sales. We actually have enough data now to start to see that effect occurring.
It’s not all about car-counting, though. We are also looking at a half-dozen other applications and I am going to talk briefly about two of them.
One of them is construction in China. If you talk to the guys in the investor community, there’s a huge division about China. Some people say they are building these things the size of lower Manhattan and nobody is living in them. Other investors believe that they are appropriately building because a large population of a billion people who are starting to move in from the countryside. Our role here is not to resolve that. Our role here is to count the buildings and count how big they are.
This is actually really hard from a machine vision point-of-view. You’re looking from above, you can’t really tell how tall these buildings are from above. Instead, we’ve been focusing on counting shadows. I just pulled out a few— these are actual tiles out of our system—to show you how challenging that is from a machine vision point-of-view.

Those are shadows, those are shadows, this is a shadow with a hole in it. This is a shadow in a really dark image. This is a shadow in a really light image, which is actually lighter than the lightest pixel in the really dark image. Nevertheless, the neural networks are getting to be pretty good at this. This is actual output, where we start from the image, we create a heat map of how likely we think each pixel is a shadow pixel and then we create our actual assessment of where the shadows are.

We’ve been running this on a set of commercial developments of known gross square footage and we found a 0.96 correlation between the shadow pixels and the known gross square footage. We’re just in the process of rolling this up to run it at a city level and then national level. The data on China is amazingly bad. One of the biggest challenges in this project is there is no good objective data to tell how good we are doing. That also means the data source, once we build it, will be one-of-a-kind in terms of how quickly people are putting up buildings in China and other countries as well.
The last one I am going to talk about is oil. As you may have noticed, the price of oil has been going down quite a lot. Part of the reason for that is the world is literally running out of places to put crude oil. What we’ve been doing here is we’ve been looking at these floating lid tanks. Crude oil is almost always kept in tanks with floating lids. This is a cutaway picture.
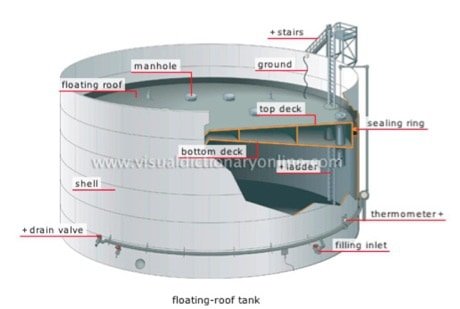
The reason they do this is that if they don’t do it, the volatile fumes from the oil will get out into the environment and they may actually explode inside the tank. The lid floats, it sits right on top of the oil, and because the lid sits right on top of the oil, it creates these nice little crescent moon shadows for us. One of our machine vision leads, Boris, has been working on this and he is here so you can find him and get him to try to tell you the secret. I am not going to tell, but he has a new algorithm that gets amazingly good results.

All the red lines on that picture are machine-generated using the algorithms. And we can actually find both the outline of the outside of the tank and the line of the shadow demarcation in the tank. By looking at the distance between these two lines and a little bit of trigonometry based on the sun angle, we can compute how far down that floating lid is.

There are about 14,000 of these tanks around the world. Nobody actually knows how much oil is in all of them. When we put this signal together as we start to scale it out, we’ll have the first real picture of how much crude oil is in the world. This is one of the biggest drivers, as with any commodity; the amount of the commodity in the world is one of the biggest drivers of the price of that commodity. This will be the first time we have a real-time picture of the amount of crude oil, especially in places like Asia and the Middle East where the data is just not good.
As I said, there are many other things we are working on: predicting crop yield using multi-spectral analysis, projecting deforestation, looking at road-building as a predictor of deforestation to identify areas that are at risk, measuring commodities. It’s an extremely long list and so on the strength of that, we raised an A Round, which has been in the press, earlier this year of about almost $9 million lead by Sequoia Capital and we are in the process of building out these and a number of other applications.

You can purchase the full transcript of all the 2015 LDV Vision Summit panels:
[Kaptur is a proud media sponsor of the LDV Vision Summit]
Photo by NASA Earth Observatory 
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”