
Flickr started it all. At it’s core, the simple idea of a place where people can share they favorite photographs. A lot has been written about what it could have been and missed opportunities. With 93 million users sharing 1 million photos daily, rejuvenated by a photo enthusiastic leadership and infused with recent high-tech acquisitions, it is breathing a second life. While there is a lot to do to catch up to its mobile-generation rivals, it is actively shedding its static image to become one of the fastest innovating photo platform. We sat down with Simon Osindero, Artificial Intelligence Architect at Flickr to learn more before his live presentation at the LDV Vision Summit .
First, a little bit about yourself. What was your path to Flickr ?

I’ve always been fascinated by science, technology and engineering. As a young kid, in rural north-west England, I’d regularly camp-out in the text-book section of our local public library reading everything I could get my hands on. At that time, I wanted to be a “genetic engineer” — at that age I thought that meant getting to design new organisms and biological systems. (Although once biotech gets to the point where that’s more feasible, it’s probably still high on my list of dream jobs!) By the time I was in high school, my intellectual passion ultimately lay with physics so I chose to attend Cambridge University to study natural sciences, with a focus on physics, molecular biology and mathematics.
I was very fortunate that not only was university education in the UK completely free, but I was also able to earn several merit scholarships to help with accommodation and books. Without that kind of financial support, I might not have been able to make the same choices that allowed me to enjoy my current successes. As such, I’m a staunch supporter of making higher education freely accessible to all — particularly those from communities that are typically under-served.
I graduated from Cambridge with a first-class Masters in Experimental and Theoretical Physics and in my last year took a fantastic course (textbook here) on information theory, taught by David Mackay. This course sparked my initial interest in Bayesian statistics, coding theory, machine learning and neural networks (thanks David!). Through him, I also became aware of a fantastic four-year neuroscience PhD program at University College London. Despite not having a neuroscience background, I was accepted to the program and found the first year incredibly challenging and rewarding, cramming in most of the courses for an undergraduate degree in neuroscience as well as the specialized graduate courses and lab rotations.
My lab rotation at UCL’s Gatsby Unit with Geoff Hinton really solidified my interest in theoretical neuroscience and machine learning, and Geoff continued as my remote supervisor during the remainder of my PhD even after he moved to Toronto. I was also fortunate enough to be advised by Peter Dayan – I’m still immensely grateful to both these luminaries for their guidance, advice and support over the years. During my PhD, my work focused on exploring links between unsupervised learning approaches, and the development and structure of neural representations in brain, specifically the parts of the brain that deal with perceptual information (ie: vision.)
After finishing my PhD, I joined Geoff Hinton for a post-doctorate in Toronto where we, along with Yee Whye Teh, proposed Deep Belief Nets in 2005/2006. That work, along with research from the labs of Yann LeCun, Yoshua Bengio and other members of Canada’s NCAP program was largely responsible for igniting the interest in what people now call Deep Learning.
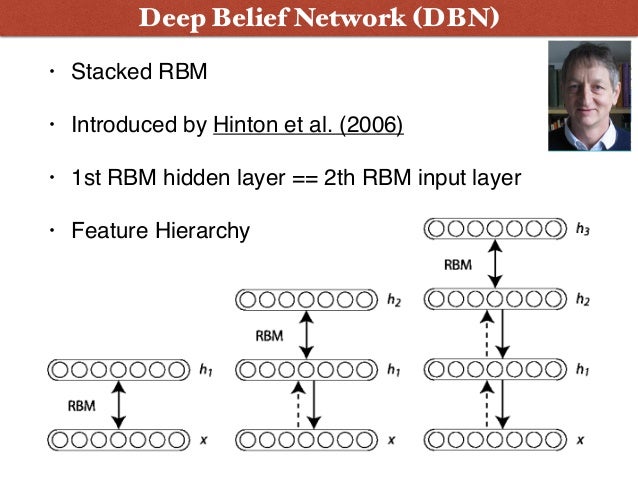
After my post-doc in Toronto, I joined a Montreal-based startup, Idilia Inc., a great learning opportunity to develop my skills in NLP and computational linguistics, and also my first significant exposure to industrial software engineering.
After a couple of wonderful years in Montreal, I had the urge to strike out and start a company of my own. I ran into a friend, Bobby Jaros, at a conference and we soon realized that our goals and interests had a great deal of overlap. I moved out to San Francisco and we co-founded LookFlow, joined by a team of fantastically talented folk (Eric Willis, Clayton Mellina, and Stacey Svetlichnaya).
At LookFlow we built a powerful new way for people to find, discover, explore, collect and share all kinds of things they’re interested in — and deep learning of representations played a big role in our technology. We combined this representation learning with a customized non-linear embedding method (related to t-sne) to produce a novel and intuitive interface for people to search, discover, and explore collections of content. LookFlow’s approach worked for a variety of domains (images, text, social networks, consumer products, movies, etc) but it was our application in the area of photography that really caught Yahoo’s eye. And Yahoo was interesting to us partly because of the rich data resources, and partly because it felt like somewhere where we could have a particularly big differential impact by introducing our machine-learning and interface technology.
We sold LookFlow to Yahoo at the end of 2013, and along with some terrific colleagues from another acquisition (IQ Engines) we’ve been working to improve machine intelligence for visual content both at Flickr and across Yahoo properties more broadly.
Are you a photo enthusiast?
Absolutely! I’ve been very passionate about photography for over 10 years. In fact, during my time in Montreal, I earned diplomas in Photography and in Digital Design from Concordia University. Unfortunately, lately I’ve not been able to shoot as much as I’d like — most of the things I capture are on my iPhone (which is now surprisingly good for photos!) and I might use my DSLR once every month or so. However, I have a bunch of photo-series in mind that I’d love to explore sometime soon!
“it’s not unfeasible that people will be able to record and store everything they see and hear in a couple of years”
What drives your research ? How do you decide what to research?
At Yahoo, the majority of our R&D efforts are product-driven, so we work incredibly closely with product managers and other engineering teams to determine where we can have the most impact in the near-term. I believe it’s important to have a good understanding of business strategy, preferred user experiences, as well as current and near-term technological capabilities. With a solid understanding of that trifecta, we can make strong strategic decisions in Yahoo’s best interests.
In addition to driving R&D work for computer vision and machine learning, our team is also responsible for a lot of the at-scale engineering implementations of those systems — and so as a group we also spend a significant amount of our time turning successful R&D ideas into production code. That’s often quite a useful feedback loop, since constraints encountered at that implementation stage can feed back into the research cycle and sometimes lead to interesting new paths.
Longer term, two of my larger personal research goals are:
(1) to help advance the broader field of machine intelligence towards creating human-level A.I. and
(2) to figure out how the brain works.
Part of my initial ambition in starting LookFlow was to land in a position where I had sufficient freedom, autonomy and resources to explore those areas without too much concern for short-term successes or other folks’ agendas, and those big questions still motivate my day-to-day efforts.

How much independence does your research for Flickr has from the rest of Yahoo and Yahoo labs in particular?
When it comes to setting our research agenda, we’re fully independent (albeit in the context of the needs of our product organization). That said, in general, Yahoo is very collaborative, and we have some fun and fruitful collaboration with other Yahoo teams.
One of the ways we make our work available within the company is through something we call “VisionKit” — a suite of software packages that other Yahoo employees can download. The goal is to share knowledge so that other engineers can easily build on fully configured environments without necessarily having detailed knowledge of computer vision or machine learning. In this way, work from our team at Flickr is already helping several other business units within Yahoo.
A lot has been written on Yahoo spending on image machine-learning companies. When will we see the first features using artificial intelligence?
A lot of work so far has been focused on improving and scaling up various parts of Flickr’s backend infrastructure to be able to perform machine learning at massive scale and to deliver those results to our users in a fast, coherent experience. Now that we have those foundations in place, you can expect to see a lot more features supported by our visual intelligence technology soon. Keep in mind, this is really just the beginning of what we can do and some of those features are already out in the wild, just in a limited or behind-the-scenes kind of way. Stay tuned!
Looking around the photo:tech space, what do you see that excites you?
There’s so much to be excited about right now — both in terms of what currently exists and what the field is thinking about.
For instance, on the hardware side you have things like the amazing advances in cards that support GPGPU computations, cheap but high quality digital cameras, storage that’s essentially unlimited and free, drone cameras, virtual-reality and augmented-reality headsets — the list goes on.

In terms of software, there’s a proliferation of amazing open-source software projects for machine learning and the surrounding ecosystem. And I’m be remiss if I didn’t take this chance to plug Caffe https://github.com/BVLC/caffe — a wonderful deep learning project from UC Berkeley that Flickr is an active contributor to. Similarly, torch and theano are fantastic open-source efforts.
Last but not least, on the algorithmic side of things, this is one of the most vibrant times for neural network research. It seems like almost monthly there’s a new record breaking result on an interesting problem. On that front, I’d perhaps single out a couple of research directions that I think are particularly promising as:
(1) shifting the focus from supervised deep learning, to semi-supervised, unsupervised, and reinforcement learning in deep models;
(2) designing curricula for learning, and also drawing inspirations from developmental biology;
(3) employing “attentional agents” or other active perception mechanisms — effectively allowing the model to determine which parts of the input to analyze (and in what ways) — an approach that can benefit very naturally from our recently improved abilities to deal with sequential models such as recurrent nets;
(4) building models that employ and integrate various types of memories and state-persistence (e.g. short-term, long-term, memory stacks and associative memory banks.); and
(5) incorporating factual and relational knowledge bases, via some kind of reasoning engine built on top of distributed representations.
I’m also excited to see increasing collaboration and openness across the broader machine learning field — and I think that it will be particularly important for research as a whole as more and more academics seem to be joining large companies. We try to be as open as possible about the work we’re doing at Flickr.

With the LDV summit coming up, what do you hope to get from it?
I look forward to both the technical and business aspects of the LDV summit – it looks like a very nice program. It’s also a great opportunity for networking with folks who have similar passions and interests.
Tell us what is interesting and unique about the LDV Vision Summit Entrepreneurial Computer Vision Challenges? Who should compete and why?
It’s a great opportunity for students, researchers, or entrepreneurs to apply their ideas to real-world problems, and to get critical feedback from technical experts and folks who have experience commercializing computer vision research.
What is your number one priority for 2015?
This year, a top priority for our team is to really build upon and expand the scope of the visual intelligence tools we offer — and deploy those tools to improve the experience of our Flickr members as well as users within the broader Yahoo ecosystem.
We have some exciting Flickr news in the pipeline with much more to follow – in many ways it feels like we’re just getting started in terms of what we’re capable of.
What would you like to create for Flickr users that technology does not yet allow you to build?
So many ideas come to mind here!! I’ll pick just one:
An interesting possibility (although one that’s admittedly fraught with social complexity) is natural semantic search for “life-logging” data.
Flickr offers all of its members 1,000 GB of free storage (imagine storing about half a million photos in one place and easily being able to manage them) and they can automatically sync their computers and mobile devices, but there’s obviously more we could do if technology allowed it. For instance, it’s not unfeasible that people will be able to record and store everything they see and hear in a couple of years — true life-logging and an augmentation of human recall. Somewhere like Flickr could one day become the secure storage and reference place for the entirety of one’s lifetime of memories (both audio and visual, including documents), as well as being a platform to share creations, communicate visually, and build community.
One of the challenges with that kind of data is how to manage and navigate the sheer volumes that are produced since for the most part, the data would be minimally annotated. We already have some promising tools for a partial solution, but there’s a lot of room for improvement. For instance, one ought to be able to colloquially describe something that happened when formulating a query, and then have the system access the right visual memories (perhaps auto-summarised) with very high precision and recall. I think we might be able to do a great job at something like about five years out from now.
![]() [ NDLR : Kaptur is a proud media partner of the LDV Vision Summit. As a reader, get up to 25% off ticket price by just clicking here.]
[ NDLR : Kaptur is a proud media partner of the LDV Vision Summit. As a reader, get up to 25% off ticket price by just clicking here.]
Photo by Vvillamon 
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”
10 Questions to an Artificial Intelligence Architect: Flickr http://t.co/zQVtKlMF7T
Where to store our lifetime memories? Simon Osindero, A.I. Architect @Flickr talks http://t.co/2oXt74wMP6 speaking @LDVVisionSummit May19NYC
10 Questions to an Artificial Intelligence Architect: Flickr #computervision #startups http://t.co/8jiqEgPb7l
“10 Questions to an Artificial Intelligence Architect: Flickr” http://t.co/MKclJWAZyK
“10 Questions to an Artificial Intelligence Architect: Flickr” http://t.co/wCf4m1vekn
Great discussion on artificial intelligence at @Flickr #deeplearning @melcll http://t.co/LmQh4PHJKq http://t.co/W2JNqhI418
Great discussion on artificial intelligence at Flickr #deeplearning melcll http://t.co/i3RNwtwJWf http://t.co/7kSkqlnyp7