
Most people are familiar with Artificial Intelligence capable of understanding images or videos and describing its content. But what about the opposite: asking the same machine to generate visual content based on a textual description? This is exactly what WordsEye solves. While the current 3D rendering might appear simplistic, this could very well be a first glimpse into the future of photography and video. Creators will no longer need to travel to capture a scene but rather just imagine it and have computers create it. We caught up with co-founder and CTO Bob Coyne to learn more:
– A little bit about you. what is your background:

I have always been equally interested in art and science. I college I majored in computer science but was also very involved in literary endeavors and served as editor of the poetry magazine. In particular, I was fascinated by the artistic possibilities afforded by computational techniques and wrote a poetry-generating program that produced surprisingly interesting results.
After college, I worked for 15 years creating commercial 2D/3D graphics authoring tools, again at the nexus of art and technology. I became frustrated, however, that the tools I was building (and others that were available) were too low level and required too much time to use. I never had time to use the tools I was building myself!
That led to the idea of using language to describe scenes. By giving up detailed control and letting the computer fill in the gaps, I felt it should be possible to shift the boundary. I became more and more interested in language processing (and a sort of return to my earlier computer poetry experiments) and went back to get my PhD in computational linguistics.
My dream is for WordsEye to open up new vistas in the nexus between art (both visual and literary) and computation.
– What does Wordseye do?
WordsEye creates rendered 3D scenes from simple descriptive natural language input. For example, typing “The cat is on the red table. It is facing left.” will position a 3D model of a cat on a 3D model of a table, with the cat facing to the left. And it will change the color of the table to red. In addition to selecting objects and giving them position, orientation, and colors, the system can also change object sizes, apply textures to objects, and change other surface properties such as transparency and reflectivity.
WordsEye works by first parsing the text input to derive the sentence structure. The parsed sentence is then converted to a semantic representation that determines what objects are involved. Specific graphical properties and relations are then assigned to those objects. At this point, various inferred objects (such as a ground terrain, a sky, and light sources) are introduced. This high-level semantics is then converted to a low-level “scene graph” that specifies exact polygonal model files with their 3D locations and material properties. The scene graph is then rendered with GPUs. All processing occurs in the cloud. The final rendered scene is then sent to the browser or mobile app via our API. Upon seeing the scene, users can then modify the input text, swap in different 3D objects of the same type, or change the camera position to view the scene from another angle.
When done, users can perform a final render at higher resolution and optionally give the scene a title and caption and add 2D effects before sharing the scene to our Gallery or to social media.
– How difficult was it to build? what challenge did you need to solve?
WordsEye is a very large system and one of the challenges is making all the components work together from language processing to graphics processing to the thousands of 3D objects and 2D images. This requires a unified approach to knowledge representation, linguistic/semantic processing, and graphical realization. For example, 3D objects require different properties so they can be properly processed. This is why putting a bird in a cage is different than putting a horse in a field or why putting a picture on a wall is different than putting a vase on a table.
Other challenges involve dealing with the many graphical limitations of the current system. And then there’s an overlay of user interface issues. For example, what is the best way to present a hybrid language/graphics interface to the user in a browser? For example, a single word can imply any number of 3D objects, so we have to provide a way for the user to choose among those objects.
One general challenge is cutting the problem down to size — to do what is feasible with limited time and resources. For example, I originally wanted to create animations from language descriptions. But I realized that we could achieve more satisfying results more quickly by narrowing down the goal to creating static 3D scenes.
– Why no verbs?
Most verbs imply actions that require posing a 3D character. For example, throwing a ball involves putting the arm in a certain position. So the same 3D model would have to deform itself into different poses. This means that all the human and animal 3D models in our library would need skeletal control structures to allow them to be posed and convey the meaning of the verb. We have some prototypes that allow that and hope to build that into the full system in the future.
– What are the commercial applications?
The online social media world is filled with visual imagery. But it’s difficult for people to really create what they can imagine. You see lots of photos and canned content variations (eg emoji, or the templates in Snapchat or Jibjab). We believe there are a huge number of people with creative visual ideas who just don’t have the skill or time to create what they can envision. By using language to open up the full power of 3D graphics, we believe WordsEye has the potential to turn everyone into an artist and open up creative visual expression and communication.
Serving as a visual expression/communication tool is one potential commercial application, but there are others. In particular, seeing words turn into pictures can help people learn vocabulary and other aspects of language.
We performed a study with 10-year-old children in a summer enrichment program. One set of kids used WordsEye to create pictures from the stories they were reading in class while a control group did their normal class literacy activities. The WordsEye group showed significantly more improvement in a literacy evaluation we administered versus the control group. Translating the scenes from the stories into the simple language required by WordsEye forced students to envision and describe aspects of those stories more concretely. And proper punctuation and spelling also helped them to get the results they wanted.
In addition, applications in various aspects of design would benefit from 3D graphics. With virtual and augmented reality, language via voice input does away with the need for a keyboard or desktop windows-style interface. One can imagine designing the layout of a room by describing the positions of furniture and other household items.
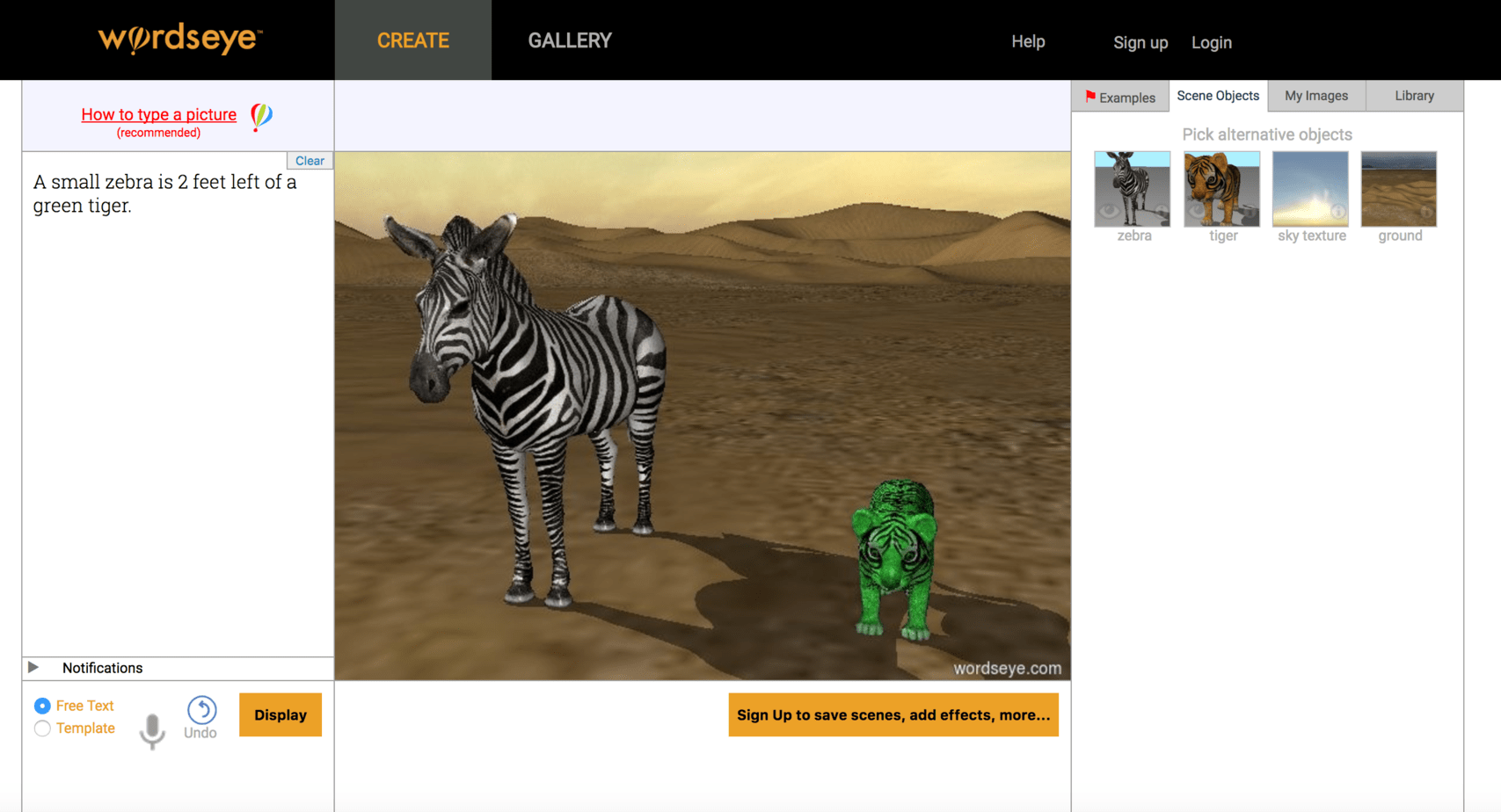
– Is Wordseye a glimpse into the future of photography whereby people will just be able to describe a picture and the computer will render it with perfection?
3D graphics allows you to create pretty much anything imaginable, not just what exists in the real world. So yes, 3D rendering can be thought of as a form of photography where you’re effectively taking a picture of an imaginary scene rather than a physical one. Unlike real photography, however, the scene doesn’t exist and needs to be created in virtual form. So WordsEye provides a quick, fun way of composing a scene and then taking a 3D rendered “photograph” of it.
– Will the next version allow for the creation of animated scenes?
Yes, though in a very limited sense. Once a user has created a scene, it is very easy to do camera “fly-throughs” where the user can select a couple of perspectives and have the system automatically transition from one to the other. Having the objects animate within the scene (eg a character throwing a ball to another) is a bigger project and beyond the scope of what we are currently trying to do. We do hope, in future versions, to support storyboard/comics output where posed characters can suggest actions.
– The graphics are very 80’s. Is it on purpose or a technical requirement?
We have a wide range of 3D models and users. If you just put a random object on a flat ground plane with default lights it won’t look great. But like any other tool, it depends on what you do with it. We have some users who create a steady stream of beautiful, visually sophisticated scenes. Part of the challenge is making it possible for all users to quickly and easily achieve those effects by default without having to learn the specific techniques.
– Any thoughts about using machine learning to extend its understanding capabilities?
Both machine learning and, even more so, crowd-sourcing will allow us to expand the power of the system. This can be at many levels, for example, even something as simple as which particular 3D object to use in a certain context. Or allowing users to build backgrounds and other compound objects with the system that can then be used out of the box by other users. But the question actually gets at another point. The system is primarily limited by what it can do graphically, rather than what it can understand. So our main goal is to enhance its graphical capabilities, both at the level of graphics processing and the underlying graphics content. For example, you asked earlier about “why no verbs”. That is a graphics (and graphical content) limitation in the current system.
– What would you like see Wordseye do that technology cannot yet deliver?
It depends on what you mean by the question….
We are looking to incorporate certain aspects of current state-of-the-art graphics into WordsEye. In particular: posable characters and shape deformations based on physics and computational geometric techniques will allow much more flexible control of scenes via language. And more sophisticated rendering capabilities in real-time, such as area lighting and atmospheric effects will bring richer visual qualities to even the simplest scenes.
As software technology continues moving off the desktop and into the world, WordsEye can provide new avenues to communicate and express oneself creatively. Language has the potential to harness the untapped power of 3D graphics by making it easier to invoke and control. Our goal is to make creative visual expression as easy as sending a text or voice message, to bring language and graphics processing technology to everyone everywhere at any time.
Photo by Jan Tik 
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”