
During last Spring’s LDV Visual Summit, there was a company whose name came up over and over during panels and side conversations: Clarifai. Still navigating under the radar, it has managed to quickly gain major recognition and recommendations from its peers in what is probably the hottest segment of photo tech : computer vision.

CEO at Clarifai
Whoever cracks the last mile code to making computer recognize and understand the content of images will dominate the internet for the next decade, if not more. Yahoo, Facebook, Microsoft, Google are pouring millions into research but it just might be two guys in Brooklyn who have the solution. We sat down with Matthew Zeiler, founder and ceo of Clarifai to learn more:
How was Clarifai created and what issue are you trying to solve?
I founded Clarifai just as I graduated NYU last Fall. I knew some of the ideas I had were promising and monumental advances in computer vision were being made using neural networks so the timing was perfect. The early work I did on Clarifai ended up winning the top 5 positions in the 2013 Imagenet challenge, an
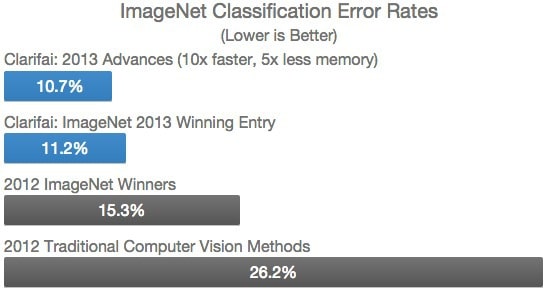
international competition for object recognition. The technology we have built solves many problems in a variety of different verticals, however it boils down to enabling computers to learn. We’ve started by enabling them to understand images and videos which enables numerous applications in consumer photos, stock photography, advertising and even medical imaging.
What are you doing that no else does ?
Our current technology combines both a classification model to automatically tag images as well as a novel similarity measure we’ve developed to enable searching for images based on their visual properties alone. Combining the two types of models provides a very powerful means of searching through and interacting with visual content. Both also scale to very large datasets while maintaining a low memory profile suitable even for mobile devices.

How far are we to 100% fool-proof results ?
I don’t believe there will ever be 100% fool-proof results for the general vision problem of understanding every piece of visual information that is consumed. Humans do not have a 100% fool-proof system either and have evolved to incorporate many shortcuts or approximations to make our visual systems more efficient or accurate depending on the scenario. The systems we’ve developed actually perform better than humans in certain situations as well.
For example, training our models on over 100 breeds of dogs can enable a very fast and accurate classifier of these various breeds that performs at or above human levels of accuracy compared to the majority of human observers. Another area where the computer models can outpace humans is in accuracy for rapid responses to image stimuli. Recent research has compared some of the final work of my NYU PhD (which has been vastly improved at Clarifai) to electrode readings from primate brains as well as Amazon Mechanical Turk workers who were shown images for 100ms and asked to categorize the object present. The deep learning system actually outperformed the primate brain and matched the human performance which processing each image in < 100ms.
Will content recognition make the need for manually entered keywords/tags obsolete?
For general categorization of images and video, automatic classification will replace the majority of manual entry. Not only is it faster, it can offer a larger vocabulary than the average user may use on a daily basis. Additionally, it provides a consistent tagging behaviour to lessen the variation in tags that users may provide. For some specific tags that may be relevant to images, such as your mother’s name, initially a system would not know that without any prior information. Therefore, a minimal amount of manual entry will likely be needed to bootstrap the systems after which they can provide automatic entry.
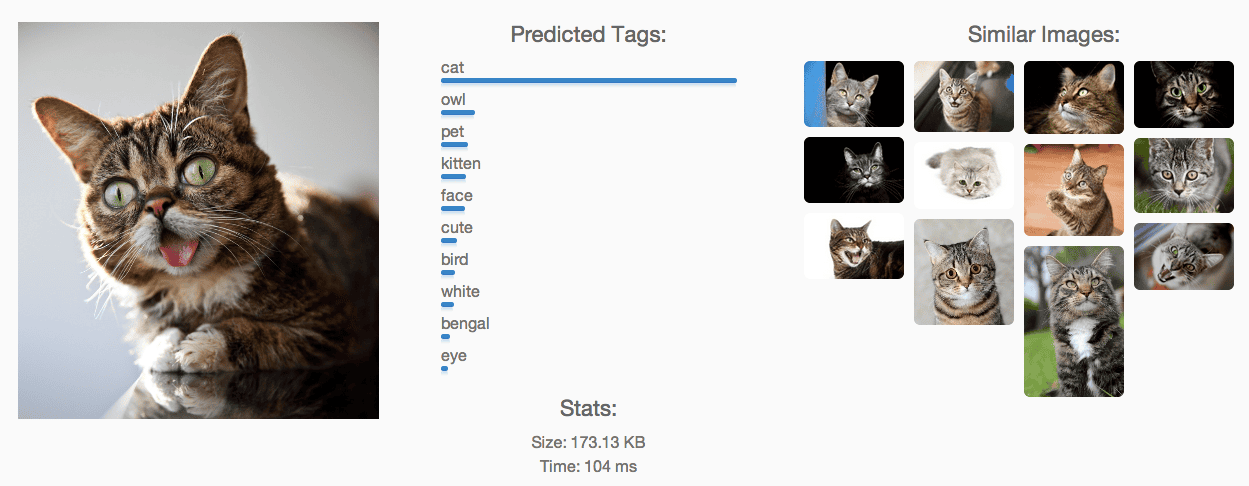
In a foreseeable future, will photos be the best tool to search ? That is, instead of a text query, you will be able to drag and drop a photo and the results will based on the content of that images?
Absolutely. It’s a much more natural way to search for visual information than text and is much quicker to query by an image than to guess a good set of search terms that would provide similar results. We can imagine applications where we utilize the camera on devices as our search box alone to create essentially a mouse for the visual world.
Who is your typical customer today ?
We are working with companies in a variety of different verticals. Stock photography, e-commerce, advertising, social networks, photo/video hosting, mobile apps, etc. all benefit from the huge gain in performance that deep learning has provided in recent years. This enables new applications in each area built upon our common infrastructure.
With giant companies like Google, Yahoo, Facebook acquiring and developing their own content recognition solutions, do you feel underfunded and under pressure ?
We don’t see these large companies as competitors other than for talented researchers and engineers. Each has their own users, data, and problems they are interested in solving. There are countless other companies with massive challenges to solve and we can step in with our expertise to help. We can also offer researchers a place to focus on huge problems while having direct impact from research to products.
How many acquisition offers did you already get ?
We’ve had several, but we’re here to build a big business. We have cutting edge technology that enables a new generation of intelligent applications which we plan to offer our customers and see through.
What would you like to offer your clients that technology cannot yet deliver?
We really want to democratize deep learning and get it into the hands of everyone. It provides noticeable leaps in performance and the implications for everyday users are tremendous. For us, vision is just the beginning and we’re already hard at work applying our technology to new modalities of data. By fusing all the available sources of data, the models can have a better understanding of the real world from which more and more interesting applications will come.
~
Feature Photo by slimmer_jimmer 
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”
10 questions for a founder : Clarifai http://t.co/XfgnOitw8e
10 Questions about @ClarifaiInc answered by the founder Matthew. http://t.co/Q350N7fKWH #qotd
10 questions for a founder : Clarifai http://t.co/lK5rjylJRa
Thanks @melchp for this interview with our CEO http://t.co/xEG0G2ZB47 . Check it out, contains some great quotes from Matt about #clarifai
RT @ClarifaiInc: Thanks @melchp for this interview with our CEO http://t.co/xEG0G2ZB47 . Check it out, contains some great quotes from Matt…