
From automatically organizing personal photos, monitoring crops, medical diagnostic, driving cars, security monitoring, computer vision is always everywhere. Not surprising since we, as human beings, use vision as our primary tool to understand the world around us. For a search engine like Google, it does make perfect sense to be one of the leaders in research. Ahead of her keynote address at the upcoming 2017 LDV Vision Summit, we spoke with Google Research Scientist Tali Dekel to learn more:
A little bit about you. what is your background?

I’m a researcher at Google in Cambridge MA, working on developing algorithms for applications in computer vision and computer graphics. Thinking back, it has been a long rewarding journey so far! My first encounter with computers was quite late, at the age of 18. When I started my Bachelor degree in Electrical Engineering at Tel-Aviv University in Israel, I knew almost nothing about what am I getting into.
Luckily, I quickly discovered my passion for science and research. I then moved to the direct track towards MSc. (when I became interested in computer vision) and then immediately towards Ph.D. I was fortunate to be surrounded by amazing people that made me develop my skills and become an independent researcher. I moved to the U.S. 2.5 years ago for my post-doc at MIT with Prof. Bill Freeman. In the beginning, I was overwhelmed by the pace things happen at MIT, which “forced” me to be at my best. Then, about a year ago, I joined Prof. Freeman’s group at Google.
– What are your responsibilities as a research scientist at Google?
We are a group of ten people (managed by Prof. Bill Freeman) and generally, our mission is to develop technology in computer vision and graphics, which is useful to the world and to Google. In Google, the approach is to be very “hands-on” and the responsibilities include the formulation of research ideas, coding, testing, collaborating and communicating with other groups within Google, and writing academic papers.
– What is the primary drive of your research? what are you primarily trying to solve?
The way we capture digital images has dramatically changed since smartphones and sharing platforms have emerged. This poses so many new problems to our field and it has been the motivation of some of my earlier work on sequencing photos captured by a crowd of people. In general, I’m very interested in developing algorithms that process larger image collections (such as all the photos of a certain person uploaded to the Web). We have so much data but we’re still lacking tools to organize, visualize and analyze it.
– Do you always start with a practical application for your research or does that come later?
It depends on how you define “practical”. Mostly, there is an application in mind which helps to motivate and focus the research, but often times there is a big gap between what is required for an academic paper and a real product.
– Your sequence of papers seem to all relate in dealing with distortion/deformation in images.
Yes, this line of work (which is part of my postdoc) deals with detecting and visually modifying small variations in digital images. When we observe structures and objects with our naked eye, we tend to idealize them. For example, buildings may seem to be perfectly straight, or repeating structures such as corn’s kernels may seem almost identical.
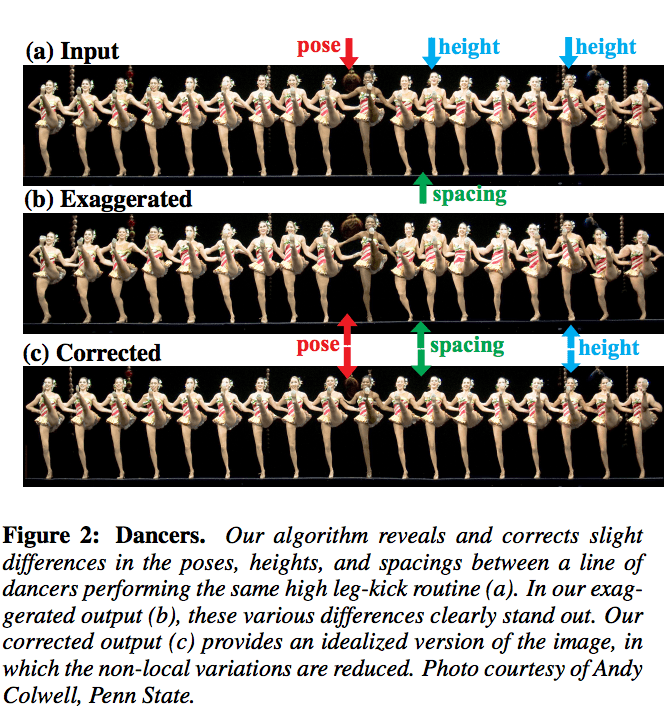
In reality, such flawless behavior hardly exists. We developed techniques that take a single image, automatically detect small imperfection/variations and render a new image in which these variations are either ironed out or exaggerated. Reducing the imperfections allows us to idealize/beautify images, and can be used as a graphic tool for creating more visually pleasing images. Alternatively, increasing the spatial irregularities allow us to reveal useful and surprising information that is hard to visually perceive by the naked eye. This work is an example of where computer vision can do even better than the human visual system.
– What area of computer vision research, outside of your own, do you feel is most exciting?
Deep learning and the use neural networks for computer vision and computer graphics applications have been a game changer in past couple of years. Many tasks that were impossible few years ago work incredibly well these days. For example, Google’s face recognition system has stunning performance which it is doing better than humans!
I’m very excited about getting into deep learning and develop algorithms that combine classic methods and established knowledge in computer vision with these powerful tools to improve our visual capabilities and hopefully obtain new ones.

– Is it challenging to be a woman in this field?
I don’t think that being a woman is the hard thing for me but rather balancing career with my other full-time job–being a mom to two young, energetic boys; this could be as hard for dads. I’m lucky to have an amazing partner that helps me making it work. Women are definitely still a minority in my field, and I’d love to see more women in my working environment. It is and I hope it will keep improving over time.
– What do you look forward to the most from the LDV Vision Summit?
I see this summit as a great opportunity to connect with top people from academia, industry, art and media, and learn about the most exciting things that those professionals are working on. I often find such events very refreshing and inspirational and I’m looking forward to it.
– Where do you see computer vision in 20 years?
I think that the way we interact with computers and other digital devices, in general, will change a lot in 20 years, and will be heavily based on computer vision. Computer vision and AI will be the core technology behind self-driving cars, virtual reality, and robotics, which will be widely used in 20 years. The main challenge would be to develop computer vision algorithms that can generalize and be interpretable. With the ever growing volume of data and computation power, it is becoming more and more challenging.
=> To learn more, please join Tali as she takes the stage for her keynote during the upcoming 2017 LDV Vision Summit.
[Kaptur is a proud media sponsor of the LDV Vision Summit.]
Photo by jonrussell 
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”