
We all read the stories and we have all heard the rumors. Latest, and probably most infamous is Google’s mislabelling of an African-American couple as “gorilla”. Proudly installed within mainstream services like Flickr and Google photos, visual content recognition is quickly getting a bad rep thanks to a few very public mishaps. For those in the know, those false positives are not a surprise. It is still extremely hard for a computer to get the content of an image exactly right, not unlike human beings. However, while we are naturally inclined to pardon our peers for making mistakes, we have zero tolerance when dealing with machines,
We thought it would be wise to run a few of the deep learning automated tagging services through a series of tests, not only to compare their accuracy but to also gauge the overall limitations.
For the purpose of this test, we took 6 images, all from either stock photo agencies or from professional photographers. Not only commercial stock ( business handshakes type) but also news and celebrity. We then took their associated metadata, hand-curated by keywords professionals, as the benchmark for the perfect result. We finally ran our small sample via a few online demos and studied the results. All images were uploaded at their original pixel resolution and the same file was uploaded to each service. The companies, each offering their own proprietary solutions, are:
Imagga IBM Watson Clarifai Orbeus Flickr
Here are the test images:
Image Number 1:

Original associated keywords:
IBM Watson results:
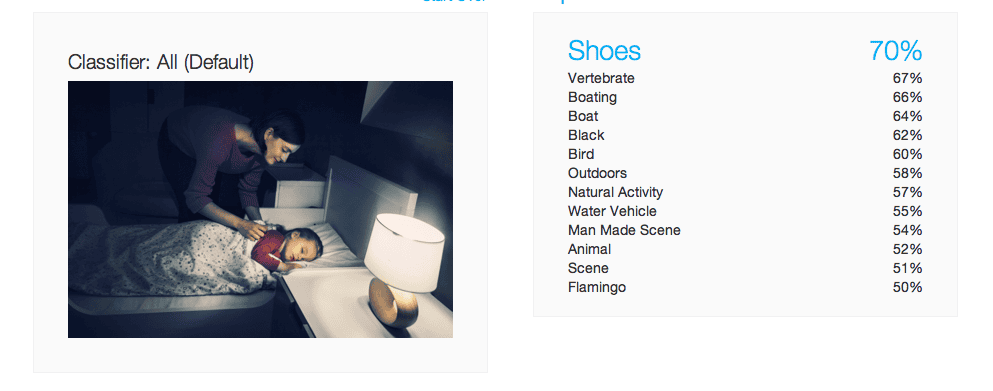
Many false positives. In fact, the majority of proposed keywords are incorrect, including ones with higher than 60% probability. Watson could not recognize the presence of two human beings.
Imagga results:
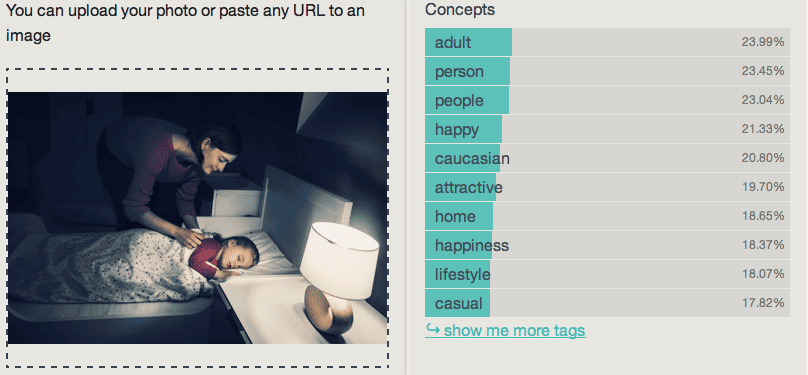
With a low probability of success threshold ( below 30%), the Imagga engine does not make any mistakes. However, the keywords are general ( “people” instead of “woman”) or vague ( “casual” which can cover a lot of cases).
Clarify :

Same as Imagga with apparently no false positives. However, the keyword “one”, probably highly rated as it sits on position number 3, is dubious. Also, boy is incorrect as per the original keyword, but to Clarifai’s engine defense, it is extremely hard to tell even for a human being.
Orbeus:

Orbeus’ engine took a lot of liberties but pulled out some verbs ( sleeping) that the others ignored. Some blatant errors like “car seat” or “towel” and some overreaching like “apartment” ( which could be correct).
Flickr :

Only two tags for the very conservative Flickr whose results are probably highly filtered to avoid any embarrassing results. Correct on both but not very helpful
Conclusion:
Due to its dark tones, this is not an easy image for a computer to analyze. Besides IBM, all engines performed well even if none were capable of revealing the key feature, the mother and child relationship it so obviously describes. Only two were able to identify the bed, also a key element of the scene. IBM Watson was frightenedly completely off the mark ( Flamingo?)
Image Number 2:

Original keywords:
soccer, kid, play, Instagram, game, child, team, movement, park, blurred, blur, afternoon, filtered, uniform, ball, field, grass, sun, scoring, tournament, score, friends, warm, kick, fun, daylight, boy, pitch, day, scrimmage, teamwork, sunny, defense, competitive, active, goal, football, run, motion, outdoors, soccer-field, competition, teammate, pass, defend, golden, player, toned, action, league
IBM Watson:

Most of the suggested words are correct. However, “Placental Mammal” or “Vertebrate” might not be the most appropriate to describe boys playing soccer. While “Nature Scene” highlighted as the most appropriate by the engine is not wrong, it is not accurate. Overall, the result is poor.
Imagga :

Imagga could not successfully recognize the type of sport played here, nor could it identify the players proper age group. The low percentage of accuracy probability overall show that the engine had a hard time coming up with exact keywords and it this case, need more advanced training. It did come up with “runner”, which is impressive.
Clarifai :

While Clarify did recognize” motion”, as well as “fun”, “group”, “speed”, along with other accurate words, it added “adult” which was its only false positive here. Soccer, however, is cruelly missing.
Orbeus :
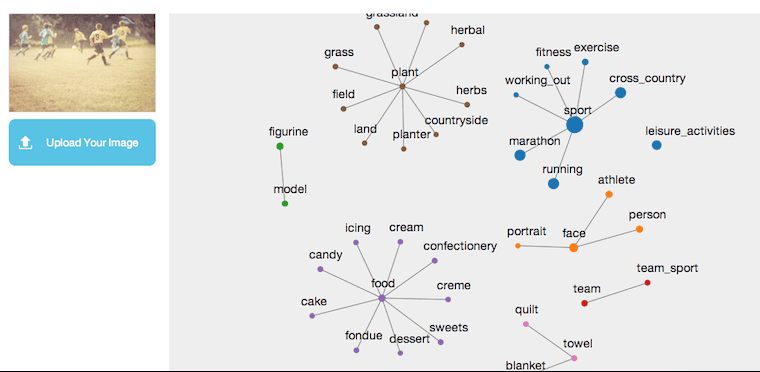
Seems like the Orbeus engine had a field day with this image. By far, the largest number of proposed keyword returned, albeit with many false positives ( quilt, towel, blanket, cake…). Only engine to recognize grass, rather prominent in the image and to suggest the verb “running”.
Flickr:

Flickr remains very succinct in its offering, as well as very general. No false positives here but then again, not very helpful either.
Conclusion:
This image was selected for its popular Instagram appearance. As well, we wanted to see how the various engines reacted to filters and artistic effect ( most of the image is in an artistic blur). While pretty easy for human beings, it has proven a hard task for machines. None could recognize the sport being played and only one recognized the grass that composes 50% of the image.
Image Number 3:

couple, beach, picnic, young, black, romantic, wine, profile, drinking, ocean, sea, man, woman, water, drinks, glasses, sitting, love, happy, smiling, African, American, summer, people, smile, happiness, relaxing, celebration, celebrating, wineglasses, holding, glass, romance, leisure, Indian, multiracial, loving, relationship, outside, outdoors, two, together, ethnic, minority, lifestyle, coast, shore, drink, copyspace, sky, Learn2Serve, crispy, food, outdoor.
IBM Watson:
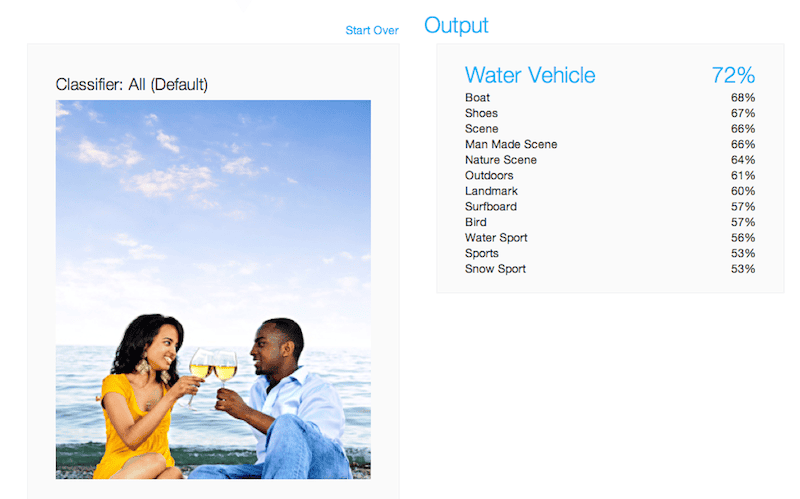
In a repeat version of previous images, IBM Watson has high confidence in items that do not appear in the image. It doesn’t even recognize the two people in the image. Poor.
Imagga :
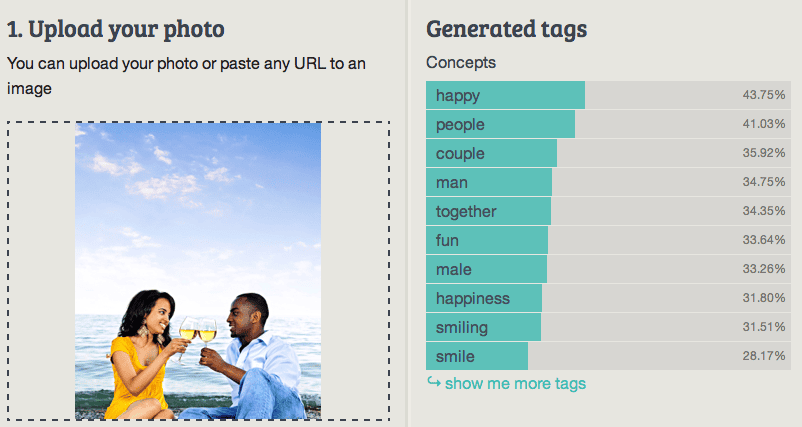
No false positives in the results shown by Imagga’s engine. However, key elements like water, glasses and sky are missing from the results, maybe because it had a lower confidence rate than 28%.
Clarifai :
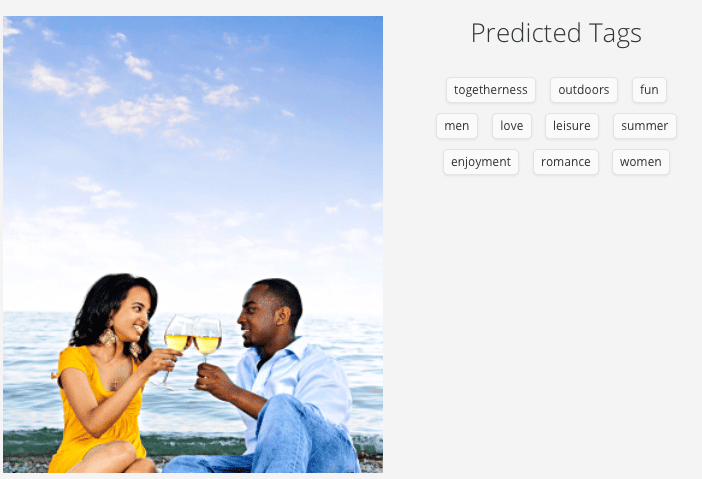
Clarifai engine also missed the water and glass elements, key to this images. It does however seem to be on target, with the keyword “love” agreeing with the original file. Note : both gender keywords while correct, are plurals.
Orbeus :

Orbeus is caught again making assumptions leading us to think that the algorithm might be set up to return linked keywords when available. For example bay, tourist, vacation are not in the original file but could be correct nonetheless. Otherwise it performs well, recognizing the people, but not the gender, drink, but not the wine (hard).
Flickr :

No risk at Flickr besides detecting a child ( maybe it’s in the couple’s future?) that is not present. It did, however, detect people, something other engines completely missed.
Conclusion:
Inspired by Google photos blunder, this test image was selected for the ethnicity of the models. However, none of the results shows any mention of race. Either the engines are not trained to recognize different types of ethnicity or their operators have turned this feature off, worried of potentially embarrassing false positives.
Image number 4 :

Original Description: LOS ANGELES, CA – SEPTEMBER 23: Keith Urban (L) and Nicole Kidman arrive at the Academy of Television Arts & Sciences 64th Primetime Emmy Awards at Nokia Theatre L.A. Live on September 23, 2012 in Los Angeles, California.
IBM Watson:

On an editorial image, IBM Watson doesn’t fair much better. While most returned keywords are correct, there are still some surprising results like “sledding” or “indoors” ( with a 62% confidence rate, nonetheless) . The appearance of the “object” keyword is also puzzling as any of the images proposed could have it as a result.
Imagga :
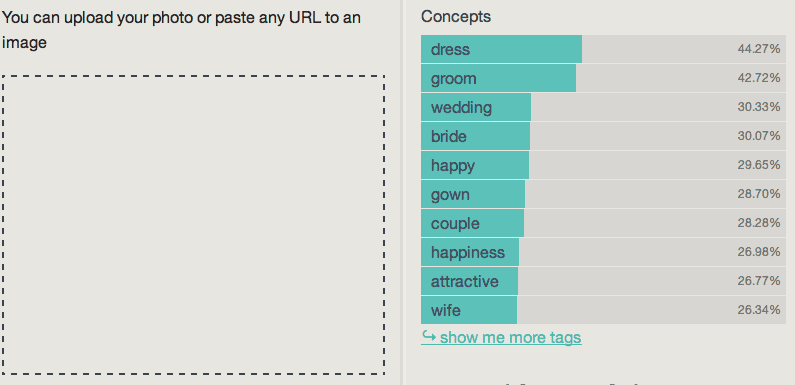
Imagga’s engine apparently thought it was looking at a wedding picture and threw related keyword. The result is a majority of unrelated keywords. The position of the couple in the frame along with the presence of a man and woman close together was probably the reason for the massive false positive.
Clarifai :
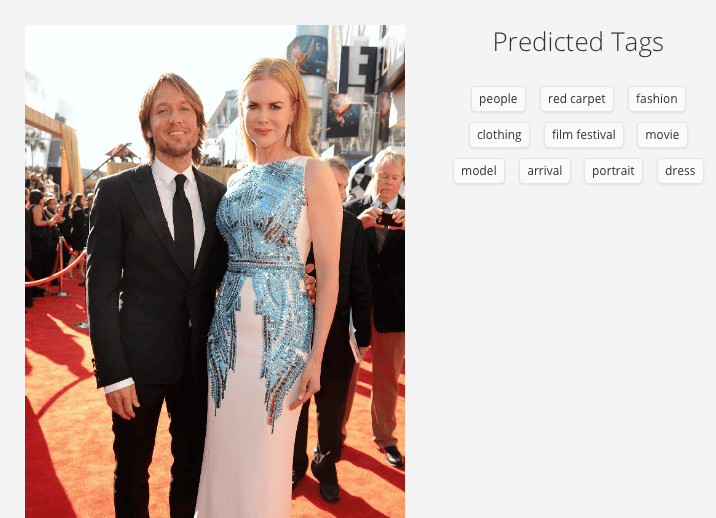
Clarifai is surprisingly accurate in its result. Apparently the engine was trained on editorial images, in particular celebrities, as keywords like “red carpet” and “arrival” reveal. The “Film Festival” tag is incorrect as the EMMY’s are Television only.
Orbeus:
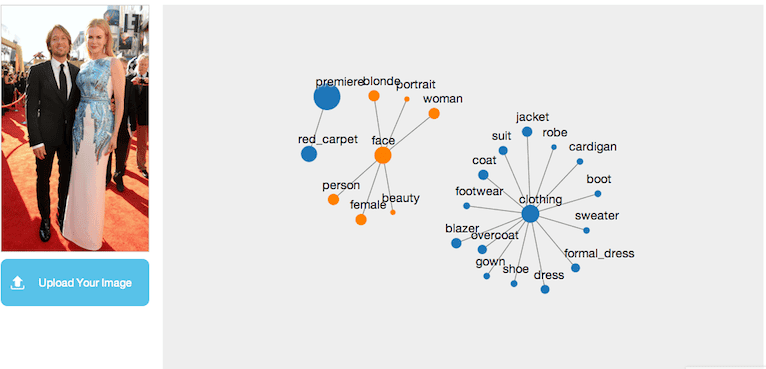
Orbeus’ engine has also apparently has been trained on editorial images as it does a good job in returning relevant keywords. A few errors in the clothing section (sweater, overcoat) but otherwise not much to throw away. We were hoping to see “Nicole Kidman ” and “Keith Urban” here as Orbeus offers a celebrity recognition engine but apparently, it is not included in their content recognition engine. On a separate test, when ran through its celebrity recognition demo, it succeeded perfectly in identifying the couple.
Flickr:

Flickr continues to disappoint as it offers only one very general tag with very little usefulness.
Conclusion:
We selected this image for two reasons. One, because of its editorial nature, it requires a different set of keywords than commercial stock images. Secondly, to test if any of our panelists would recognize the famous couple. Apparently neither Imagga nor Watson have been trained on editorial images, at least for now, and none include a face recognition solution. Overall, while the results were promising for the engines trained in editorial content, this image reveals that some engine are still too image category specific.
Image number 5:

Original description : President Barack Obama and Vice President Joe Biden, along with members of the national security team, receive an update on the mission against Osama bin Laden in the Situation Room of the White House, May 1, 2011. Seated, from left, are: Brigadier General Marshall B. “Brad” Webb, Assistant Commanding General, Joint Special Operations Command; Deputy National Security Advisor Denis McDonough; Secretary of State Hillary Rodham Clinton; and Secretary of Defense Robert Gates. Standing, from left, are: Admiral Mike Mullen, Chairman of the Joint Chiefs of Staff; National Security Advisor Tom Donilon; Chief of Staff Bill Daley; Tony Blinken, National Security Advisor to the Vice President; Audrey Tomason Director for Counterterrorism; John Brennan, Assistant to the President for Homeland Security and Counterterrorism; and Director of National Intelligence James Clapper. Please note: a classified document seen in this photograph has been obscured.
IBM Watson:
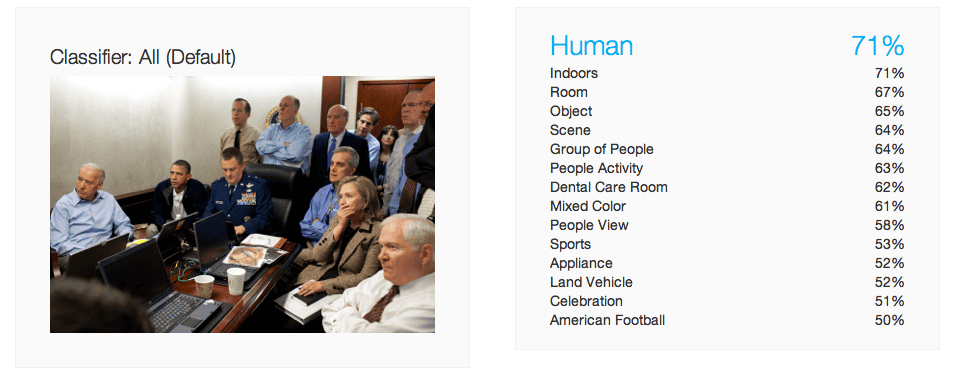
Probably one of the best result for Watson on this news image, at least for the top return ( above 62%). It then returns to its fantasy world, with confusing keywords such as “Dental Care room”, “Land Vehicle” or “American Football”. We won’t even try to figure how it got to such conclusion.
Imagga:

Again here, Imagga shows that it has not been trained on editorial images: All these keywords correspond to those one would find in a stock image. The result is mismatch tags with little relevance to the content.
Clarifai :

Clarifai goes all the way to even recognize the President, which is a surprise, considering it didn’t seem to care about Nicole Kidman previously. All of the keywords work, including the very relevant “government”. Impressive result.
Orbeus:
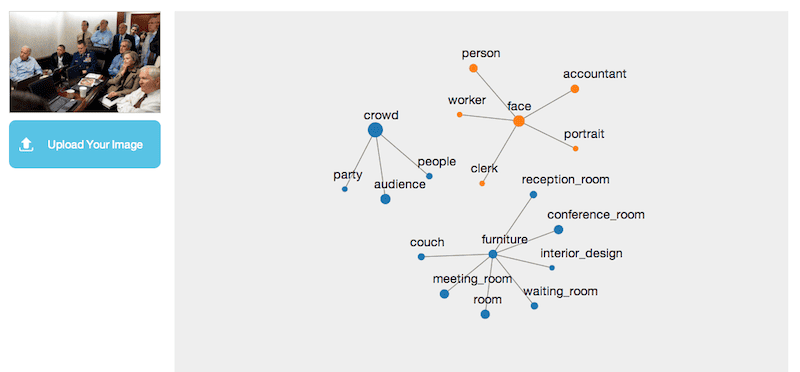
Not much to keep on the Orbeus result. A few general items like “conference room” or “people” are correct but the rest of the suggestions are poor or wrong. Disappointing considering the good result on the other editorial image in this test. Apparently, it was train on celebrity images but not news events.
Flickr:

No comment.
Conclusion: The news image baffled more engines than the celebrities on the red carpet. Apparently news photography is a not content for which engines have been trained. But that could change, depending on when the market picks up.
Overall, this short test confirms what we already knew. Content recognition engines make mistakes and cannot yet operate without human editing. As the companies offering content recognition services continue to train their machines, the better the results will become. In parallel, as high-level research continues in this field, whether from academia or by private industries, we can expect smarter algorithms to hit the market. 2015 is the first year where we can see so many public applications of visual content recognition ( Flickr, Google photos, hundreds of apps) and the resulting feedback will also bring very valuable data to engineers. Finally, it is always important to remember that with deep learning, the learning data set is as important as the algorithm and while the above results might seem overall weak, all of these engines would perform brilliantly if given related images prior to the test. In other words, for anyone looking to implement visual content recognition, the key is to feed the engines with the proper learning data.
A year from now, when we return to redo this test, we will probably witness impressive progression.
Photo by HighTechDad 
Author: Paul Melcher
Paul Melcher is a highly influential and visionary leader in visual tech, with 20+ years of experience in licensing, tech innovation, and entrepreneurship. He is the Managing Director of MelcherSystem and has held executive roles at Corbis, Gamma Press, Stipple, and more. Melcher received a Digital Media Licensing Association Award and has been named among the “100 most influential individuals in American photography”
Visual content recognition : A test drive http://t.co/UDKKrUoXRn
Visual content recognition : A test drive – We all read the stories and we have all heard the rumors. Latest, and … http://t.co/VW6chx5Tzr